【智谱「清影」同源-CogVideoX】部署教程
1. 前置准备
注册算力云平台:星海智算 https://gpu.spacehpc.com/
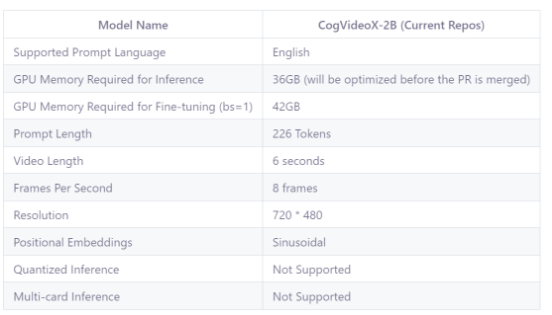
由于对于硬件的需求,推荐使用显存≥18GB的卡进行创建
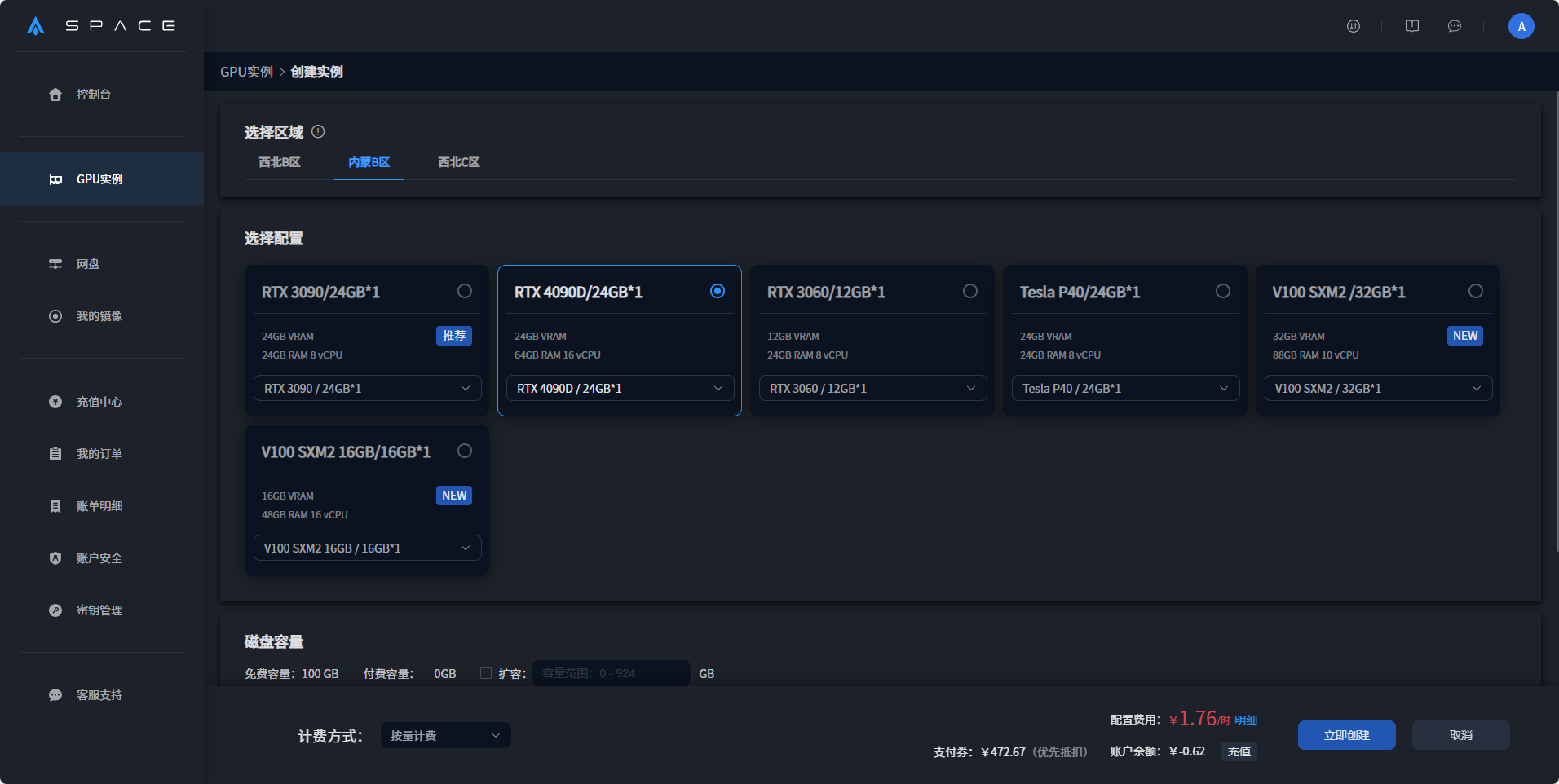
1.1 创建并启动实例
2. 相关依赖以及库文件安装
2.1 设置学术加速
由于需要访问外网,因此需要设置学术加速,学术加速的相关规则请见:学术加速
bash
source /etc/network_turbo2.2 安装库以及相关依赖
bash
pip install modelscope
pip install torch
pip install accelerate
pip install sentencepiece

bash
pip install --upgrade opencv-python transformers
pip install git+https://github.com/huggingface/diffusers.git@878f609aa5ce4a78fea0f048726889debde1d7e8#egg=diffusers # Still in PR
3. 配置相关文件
打开Notebook
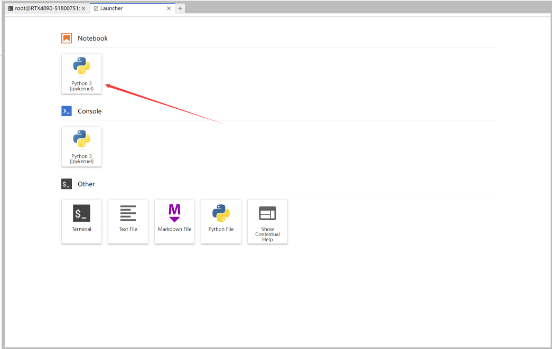
复制代码进ipynb文件
py
import torch
from diffusers import CogVideoXPipeline
from diffusers.utils import export_to_video
from modelscope import snapshot_download
prompt = "A panda, dressed in a small, red jacket and a tiny hat, sits on a wooden stool in a serene bamboo forest. The panda's fluffy paws strum a miniature acoustic guitar, producing soft, melodic tunes. Nearby, a few other pandas gather, watching curiously and some clapping in rhythm. Sunlight filters through the tall bamboo, casting a gentle glow on the scene. The panda's face is expressive, showing concentration and joy as it plays. The background includes a small, flowing stream and vibrant green foliage, enhancing the peaceful and magical atmosphere of this unique musical performance."
model_dir = snapshot_download("ZhipuAI/CogVideoX-2b")
pipe = CogVideoXPipeline.from_pretrained(
model_dir,
torch_dtype=torch.float16
).to("cuda")
prompt_embeds, _ = pipe.encode_prompt(
prompt=prompt,
do_classifier_free_guidance=True,
num_videos_per_prompt=1,
max_sequence_length=226,
device="cuda",
dtype=torch.float16,
)
video = pipe(
num_inference_steps=50,
guidance_scale=6,
prompt_embeds=prompt_embeds,
).frames[0]
export_to_video(video, "output.mp4", fps=8)4. 结果输出
点击运行


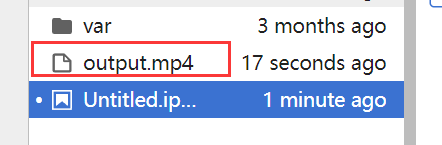
output.mp4为输出的视频文件,注意在后续的输出时需要更改输出文件的名称,防止对之前的文件进行覆盖
bash
export_to_video(video, "output.mp4", fps=8) //修改output.mp4为你喜欢的名称 例如test.mp4