【Musetalk】使用教程
镜像介绍
MuseTalk 是由腾讯团队开发的先进技术,项目地址:https://github.com/TMElyralab/MuseTalk,它是一个实时的音频驱动唇部同步模型。该模型能够根据输入的音频信号,自动调整数字人物的面部图像,使其唇形与音频内容高度同步。这样,观众就能看到数字人物口型与声音完美匹配的效果。MuseTalk 特别适用于256 x 256像素的面部区域,且支持中文、英文和日文等多种语言输入。
MuseTalk 可应用于多种场景,包括但不限于:
- 视频配音与唇同步:制作配音视频时,MuseTalk 能够根据音频调整人物的口型,从而提升视频的真实感和观看体验。
- 虚拟人视频生成:作为一整套虚拟人解决方案的一部分,MuseTalk 可以和 MuseV(视频生成模型)配合使用,创造出高度逼真的虚拟人演讲或表演视频。
- 视频制作与编辑:在视频制作和编辑中,当需要更改角色台词或语言而不愿重新拍摄时,MuseTalk 提供了一个高效的解决方案。
- 教育和培训:在教育领域,MuseTalk 可以用于制作语言教学视频,帮助学习者更准确地学习语言发音和口型。
- 娱乐与社交媒体:内容创作者可以利用 MuseTalk 为照片或绘画作品添加口型动画,创造有趣的视频内容分享至社交媒体,为粉丝提供新颖的互动体验。
使用教程
1、注册算力云平台:星海智算
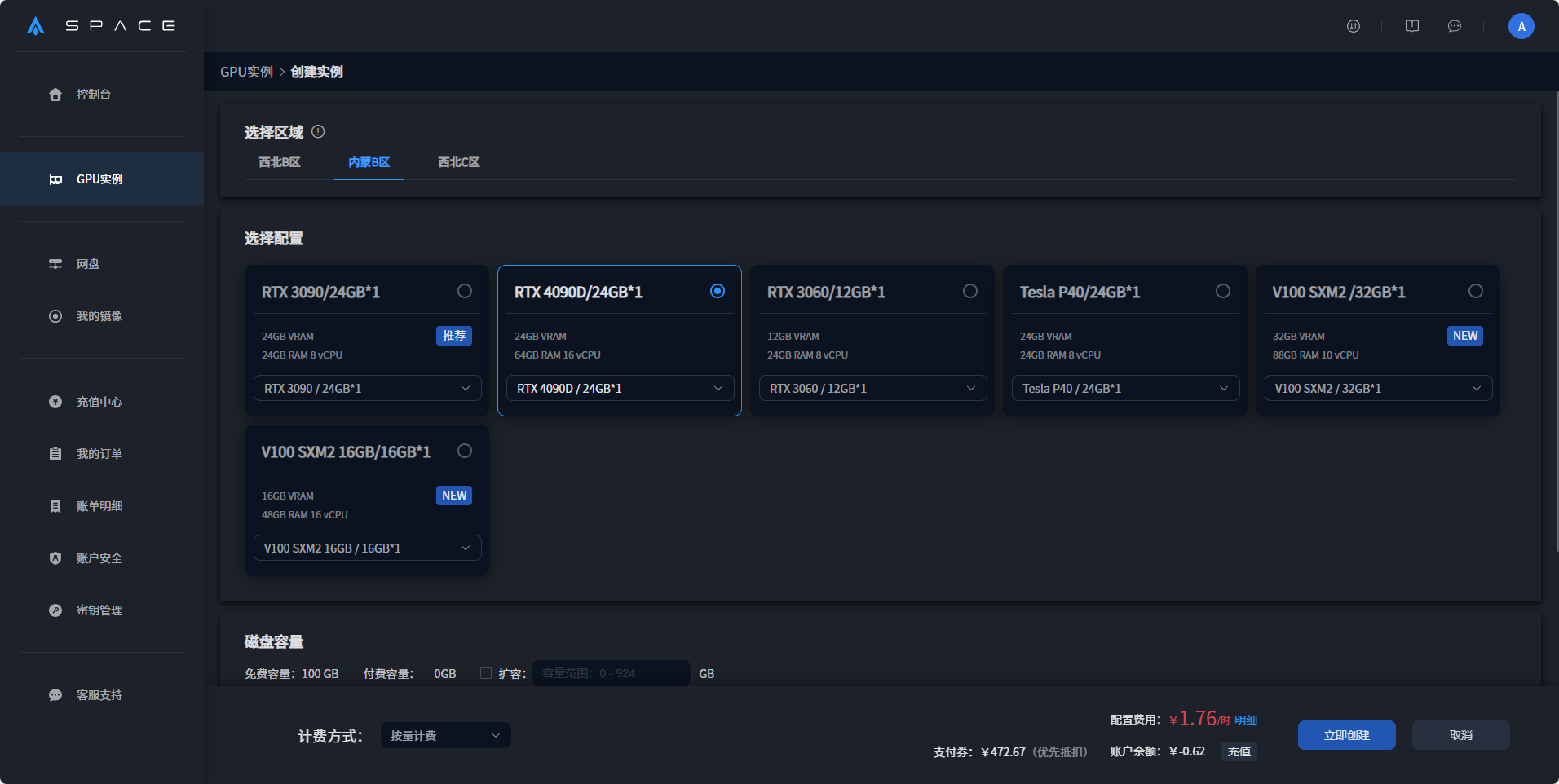
2、选择区域并根据运行需求选择合适的显卡
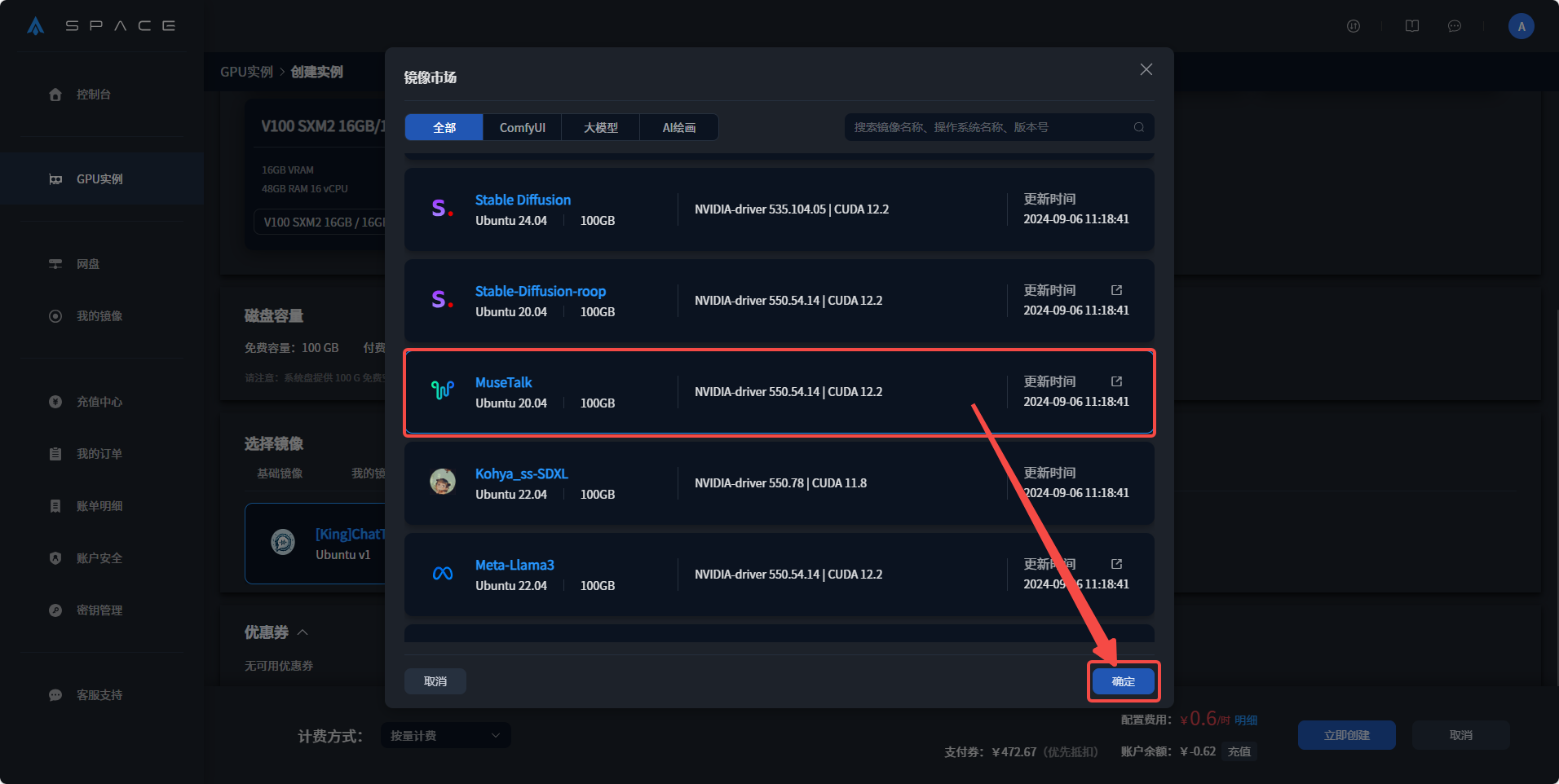
3、选择镜像市场,点击更换镜像,选择Musetalk,点击立刻创建,等待运行成功即可开始使用。
该镜像使用ssh连接,连接步骤详见快速使用教程
命令行推理
内置 jupyter notebook,当然你也可以使用命令行运行。
普通推理
设置工作目录并运行
bash
cd /root/MuseTalk/
python -m scripts.inference --inference\_config configs/inference/test\_img.yaml
python -m scripts.inference --inference\_config configs/inference/test\_video.yaml生成结果位于 results 目录
实时推理
目前实时推理功能只是模拟的demo,有兴趣可以测试一下。
注意:
对于每一个人物图像,都需要把 configs/inference/realtime.yaml 配置文件中的 preparation 设为 True 执行一次即可,bbox_shift 修改后也要这样操作!之后如果继续使用这个人物图像就把 preparation 设为 False。
实时推理命令
bash
python -m scripts.realtime\_inference --inference\_config configs/inference/realtime.yaml