Llama3.2 Vision(90B+11B)使用说明
(一)前言
1、磁盘空间
占用33G磁盘,预留了近67G磁盘空间以供用户使用。 
2、模型介绍
Llama 3.2-Vision 多模态大型语言模型 (LLM) 集合是一个包含 11B 和 90B 尺寸的指令微调图像推理生成模型的集合(文本 + 图像输入 / 文本输出)。Llama 3.2-Vision 指令微调模型针对视觉识别、图像推理、字幕生成和回答有关图像的一般问题进行了优化。在常见的行业基准测试中,这些模型的性能超过了众多现有的开源和闭源多模态模型。
支持的语言:对于纯文本任务,官方支持英语、德语、法语、意大利语、葡萄牙语、印地语、西班牙语和泰语。Llama 3.2 已在比这 8 种支持语言更广泛的语言集合上进行训练。dsfsdfdsfdsfsdfs
请注意,对于图像 + 文本应用,仅支持英语。
(二)使用详情
应用服务(以11B)为例
实例创建完成后,滑动下方滚动条,在实例右侧有应用服务按钮,点击打开界面。

若出现“502 Bad Gateway”建议关闭界面等待两到三分钟重新启动,若还是出现问题,联系工作人员。

打开界面如图所示。
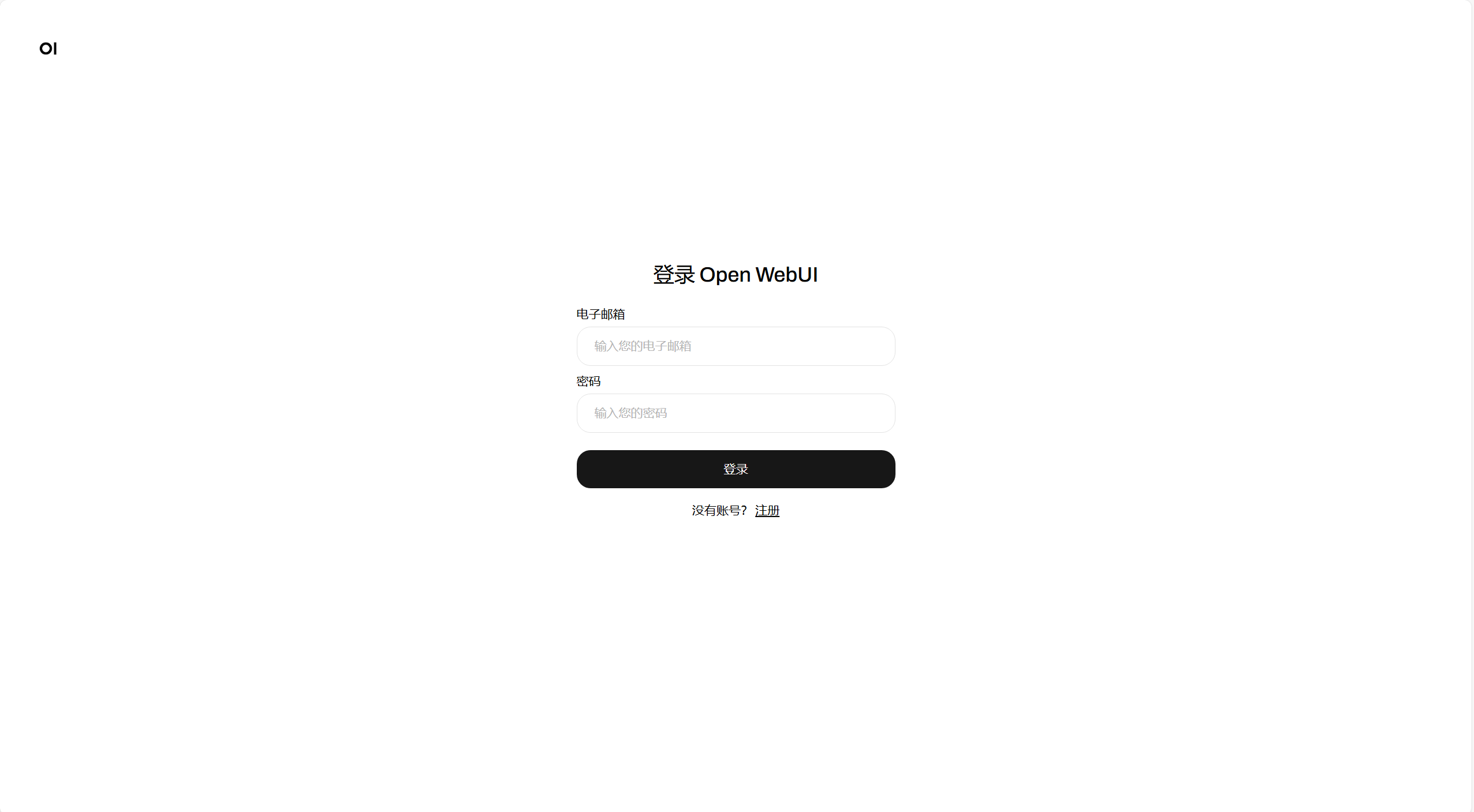
首次登录需要注册管理员账户,点击下方注册,输入账户名,邮箱,密码完成注册。
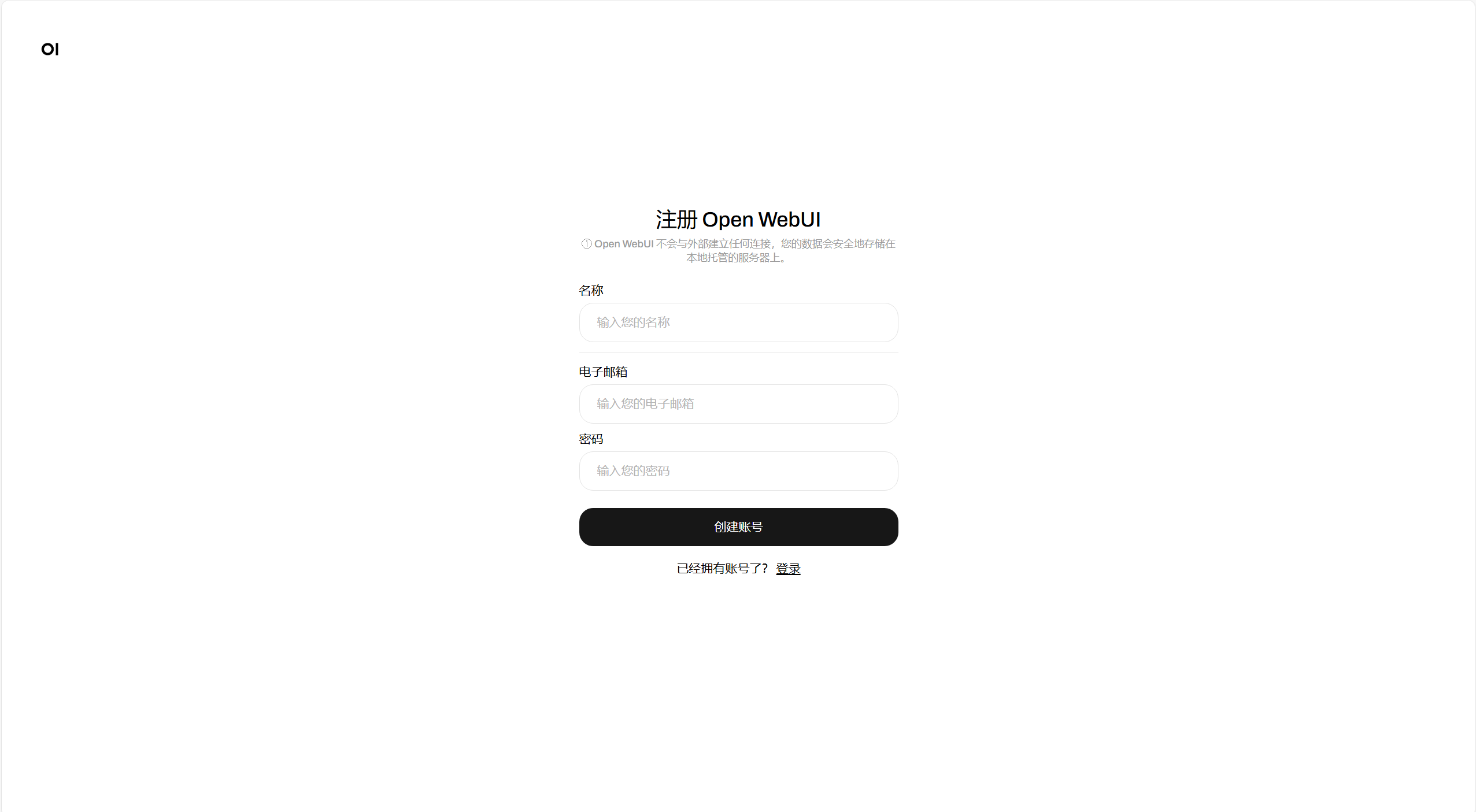
点击左上角Arena Model按钮选择需要的大模型,目前已内置Llama3.2 Vision 11B多模态大模型以及Llama3.2 3B大模型。
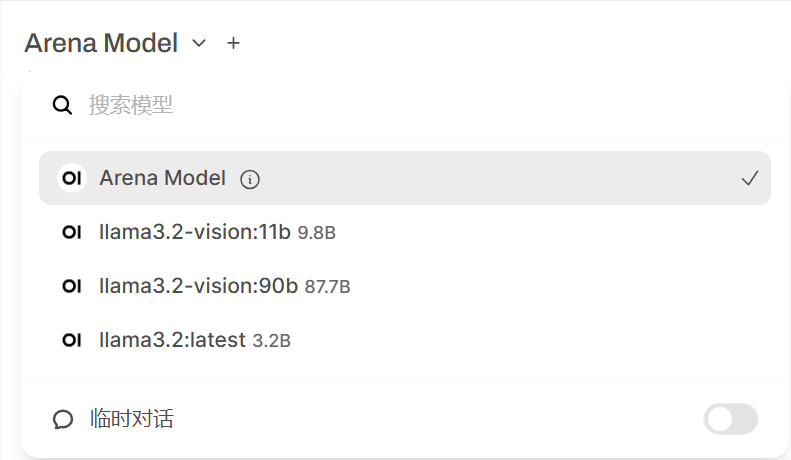
选择好模型后,在输入框添加图片,使用英文进行对话。
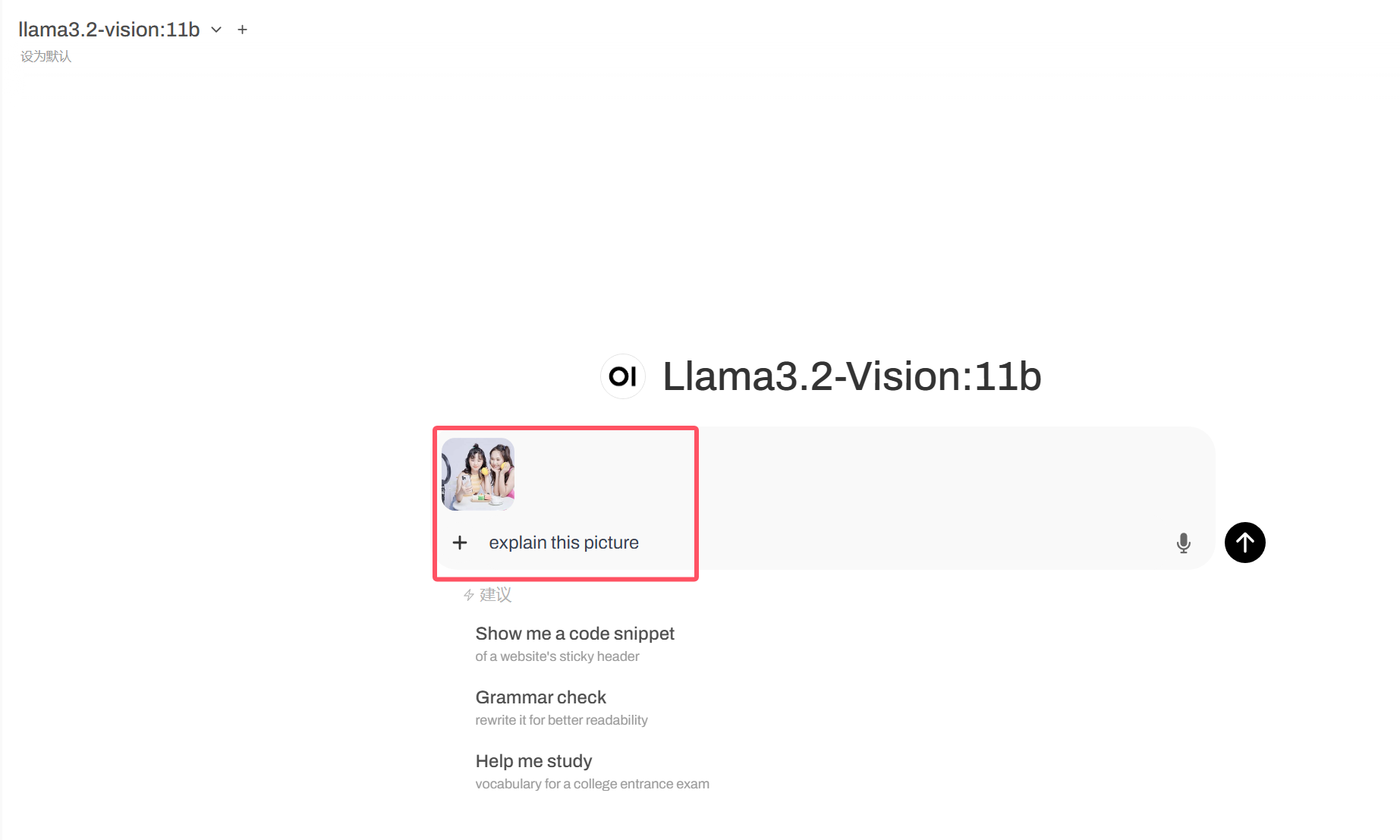
等待片刻,即可收到Llama 3.2-Vision识别图像后的回复。
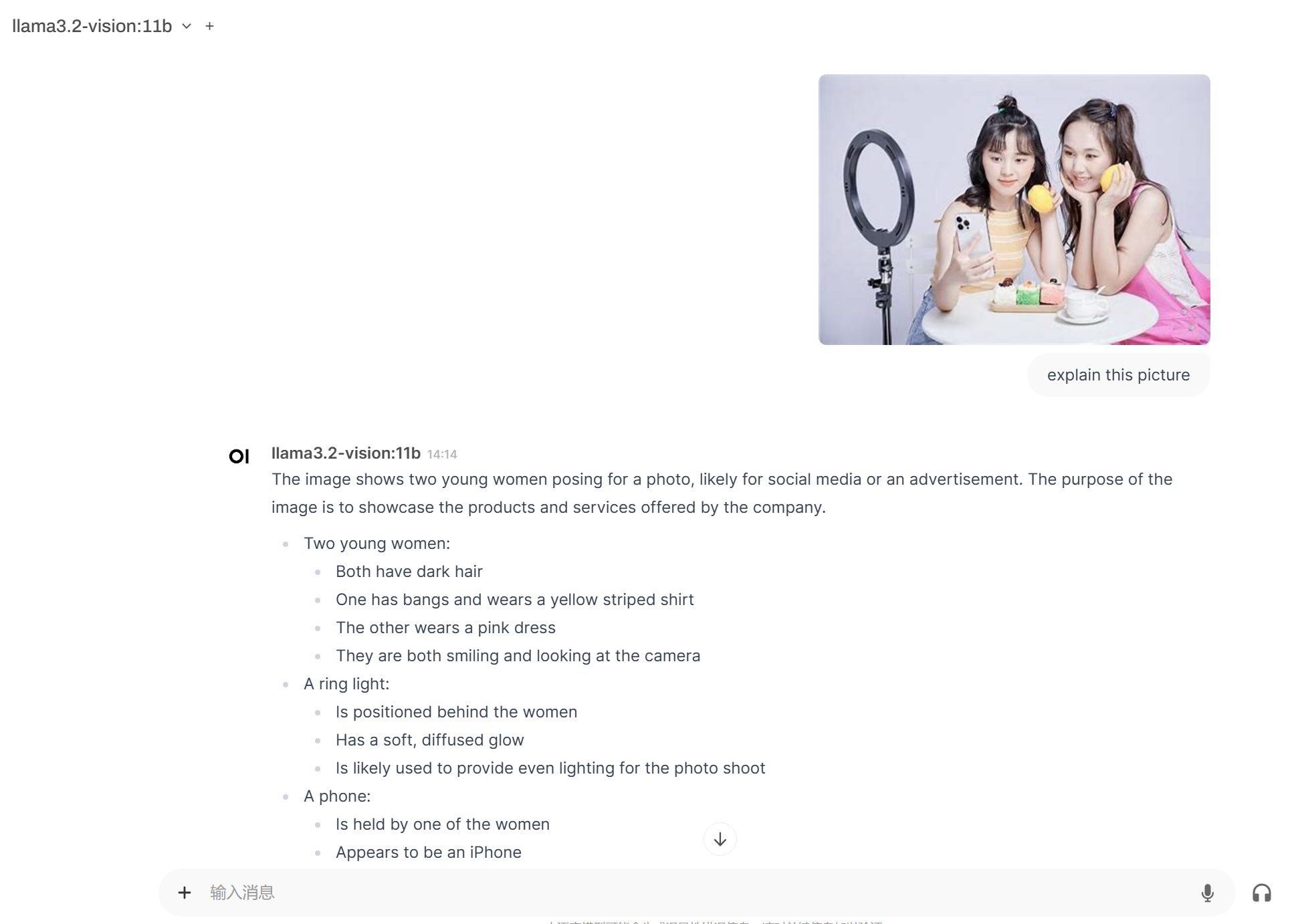
切记,对于图像 + 文本应用,仅支持英语对话。