【SVC-Fusion1.1.1】部署教程
SVC-Fusion1.1.1介绍
SVC-Fusion1.1.1 : 开箱即用的 AI 翻唱音频工具箱

SVC-Fusion 是一款开箱即用的 AI 翻唱音频工具箱,核心定位为 “低门槛、多功能”,面向小白用户且无需显卡即可训练,其功能特征可从「核心定位与优势」「支持的 AI 模型」「关键功能特性」「一站式工具集」四大维度展开
主要功能特征
| 功能类别 | 具体功能 | 价值说明 |
|---|---|---|
| 硬件适配 | 50 系 N 卡支持 | 兼容新一代 N 卡,提升硬件利用率 |
| AMD 显卡支持 | 打破 “仅支持 NVIDIA 显卡” 限制,覆盖更多用户 | |
| 模型定制 | 自定义底模 | 支持用户根据需求替换基础模型,提升个性化程度 |
| 自定义声码器 | 可更换声码器类型,优化音频输出音色 | |
| 音频处理 | 音区偏移 | 调整音频音调范围,适配不同声线需求 |
| 内置离线分离 | 无需联网即可分离人声与伴奏,提升使用灵活性 | |
| 自动混音 | 自动优化多音频轨道混合效果,减少手动操作 | |
| 实时功能 | 实时变声器 | 支持即时语音转换,可用于直播、互动等场景 |
| 声码器变调 | 通过声码器精准调整音调,保持音频自然度 | |
| 系统管理 | 完整的模型管理系统 | 统一管理已安装 / 训练的模型,方便切换与维护 |
1. 前置准备
1.1 创建实例
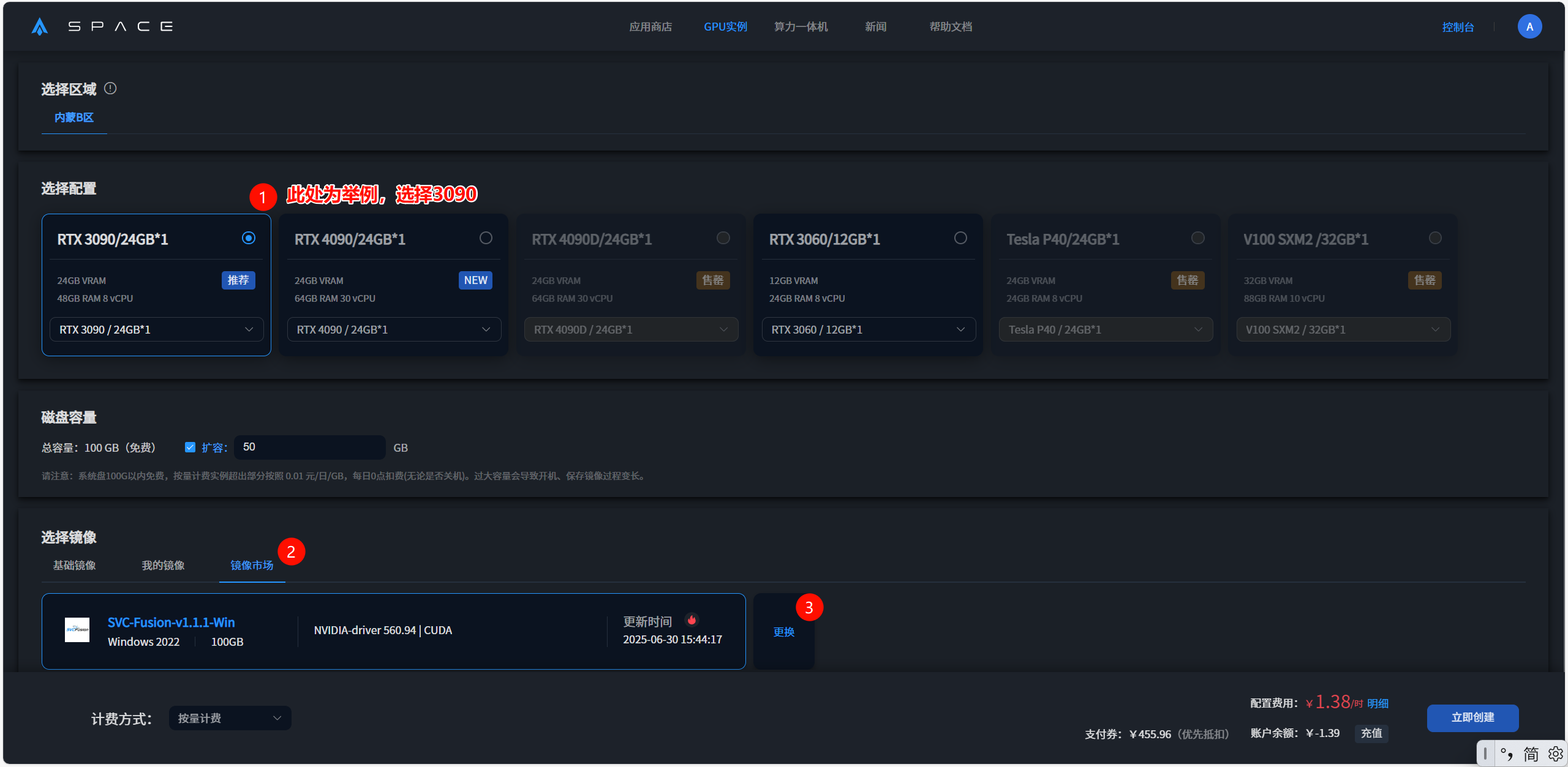
选择配置后,在镜像市场中搜索SVC,即可找到SVC-Fusion-v1.1.1-Win,点击立即创建
1.2 添加音频
在选择好分区后,将本地的音频素材直接拖动到网盘中

1.3 启动JupyterLab,并打开程序
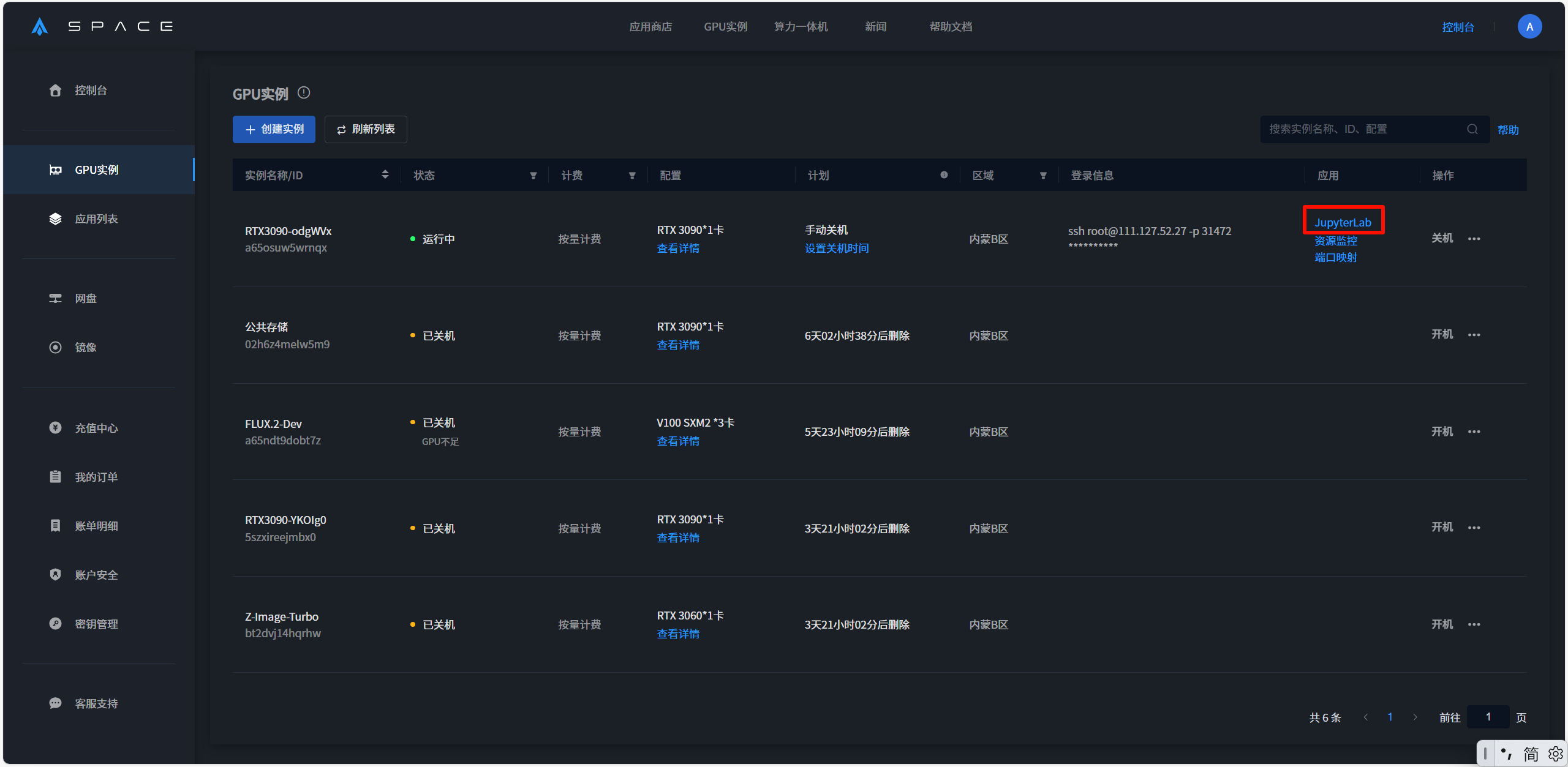
打开后点击 + 号,再点击终端,输入以下指令
linux
cd /root/svc-fusion
source env/bin/activate && python -V && python launcher.py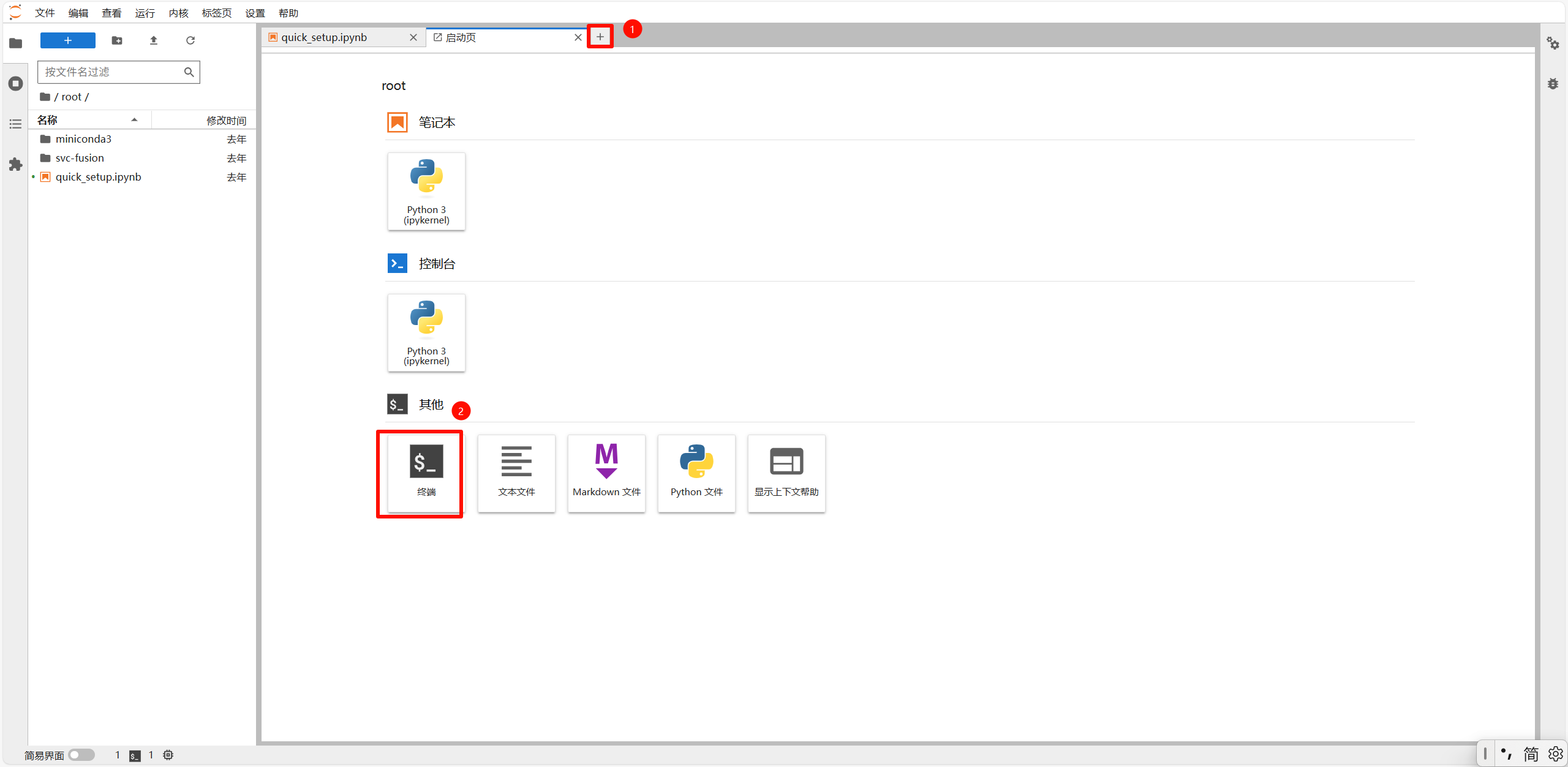
启动完成后按下图所示操作
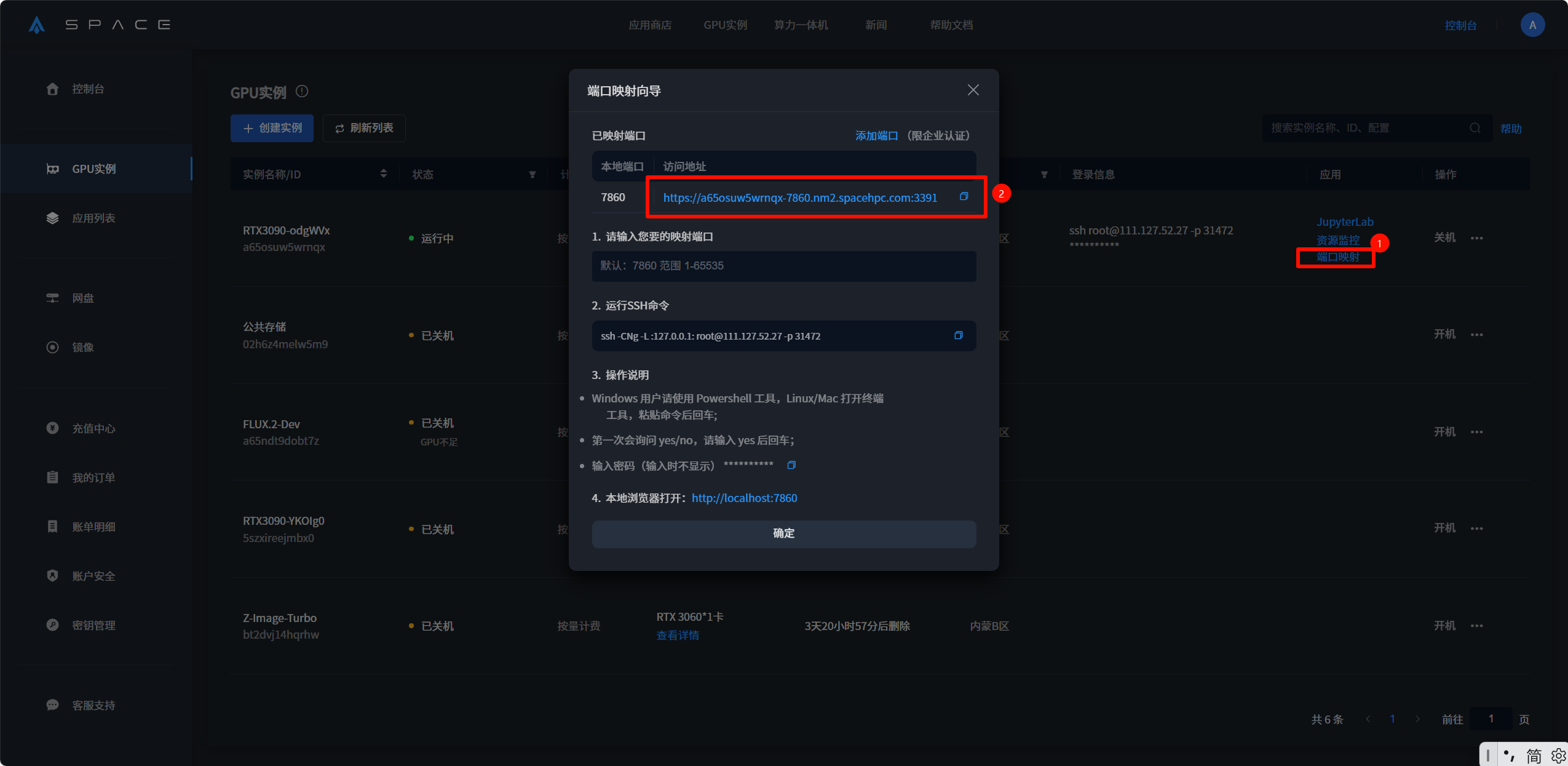
回到JupyterLab界面,按如图所示操作
1.先将路径选择至dataset_raw,右键创建文件夹,再在终端窗口执行 指令
cp /mnt/storage/1.wav /root/svc-fusion/dataset_raw/所创建文件夹名称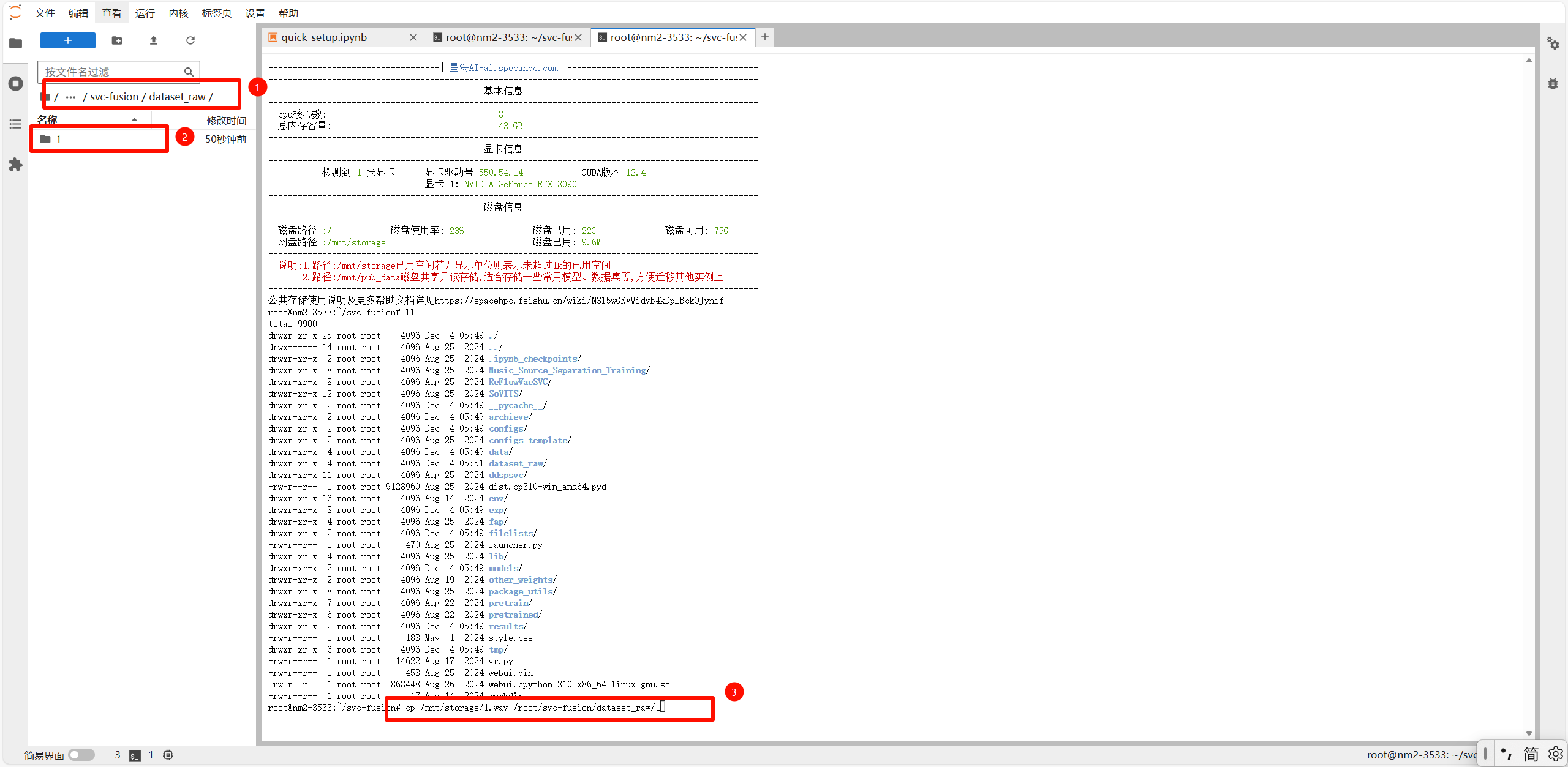
2.SVC-Fusion1.1.1演示
访问localhost:7860,即可看到该页面(运行完成后也会自动跳转)
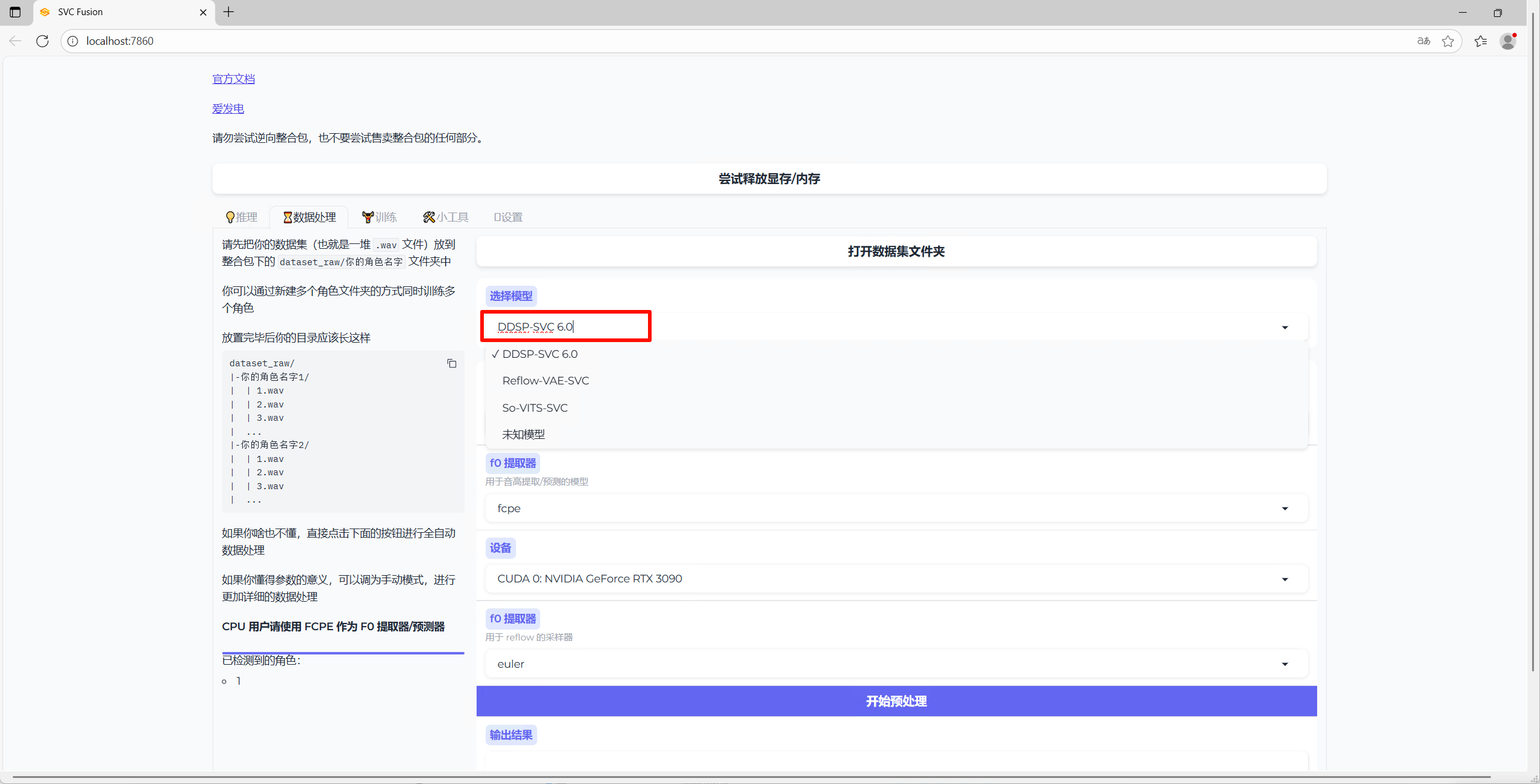
此教程以演示模型DDSP SVC 6.0为主
2.1数据处理
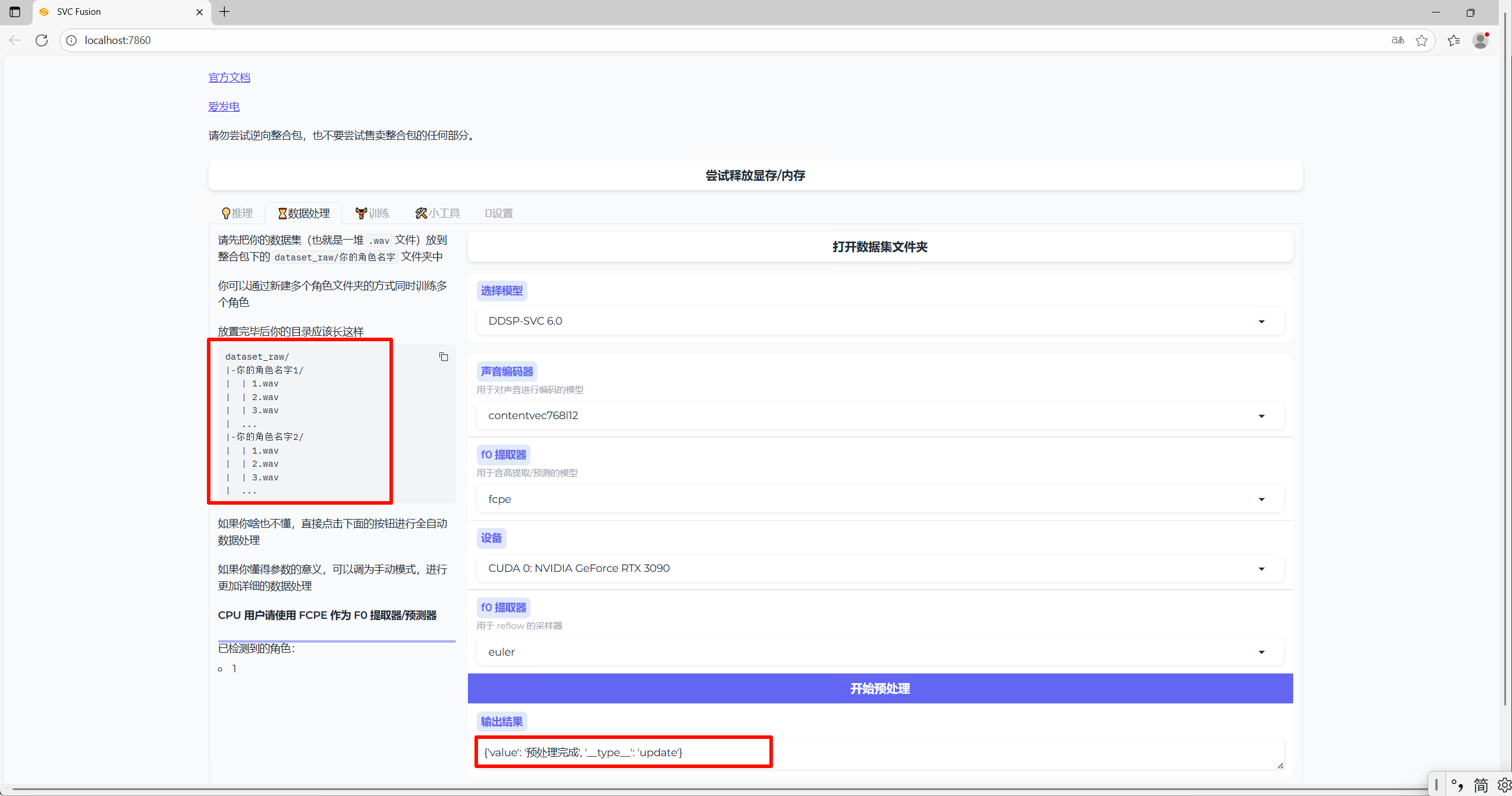
- 选择数据处理tab页,选择模型为DDSP SVC 6.0,点击开始预处理
如下图所示,即预处理完成
2.选择训练tab页修改配置,点击开始/继续训练
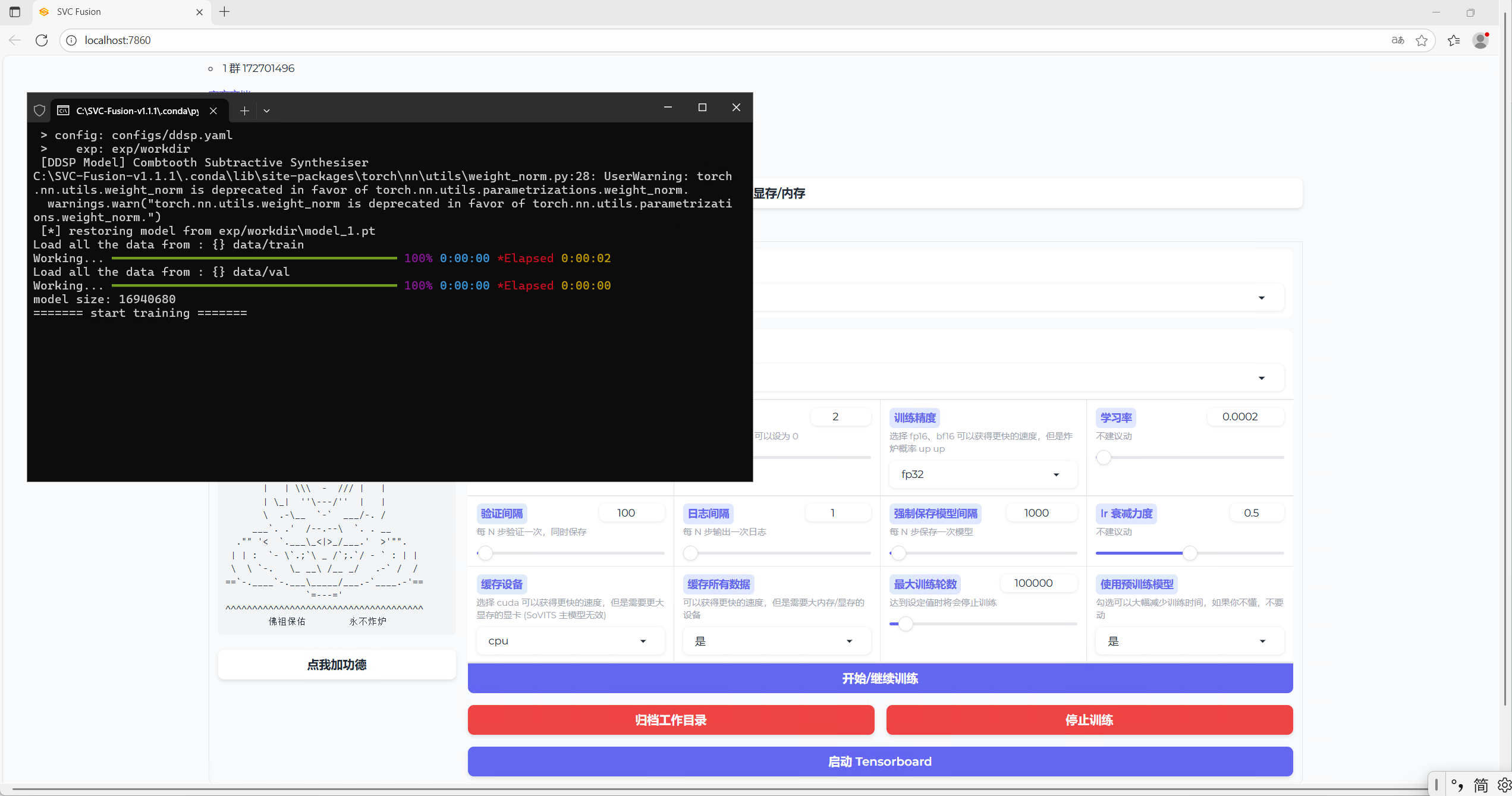
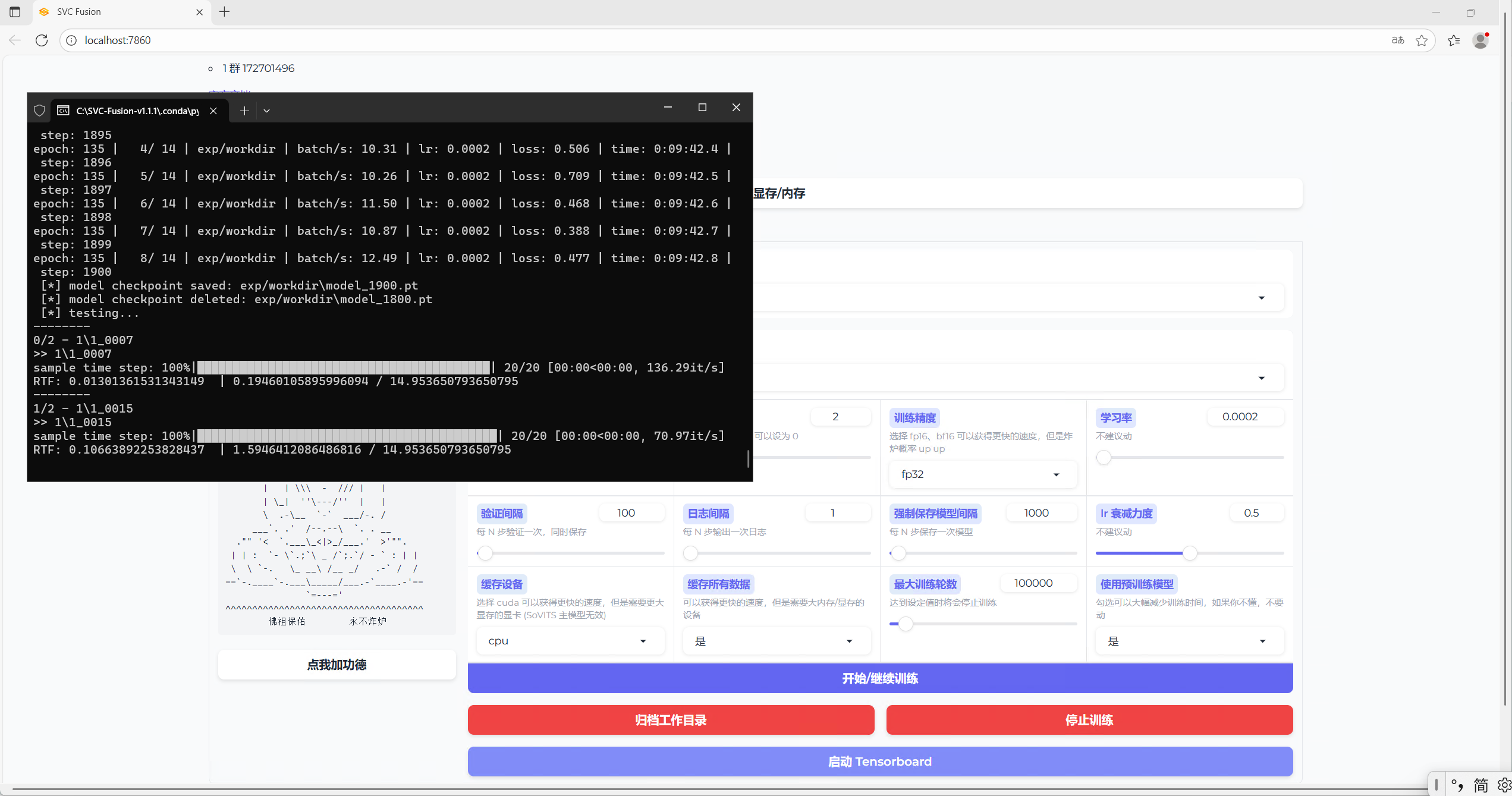
如图所示即训练完成
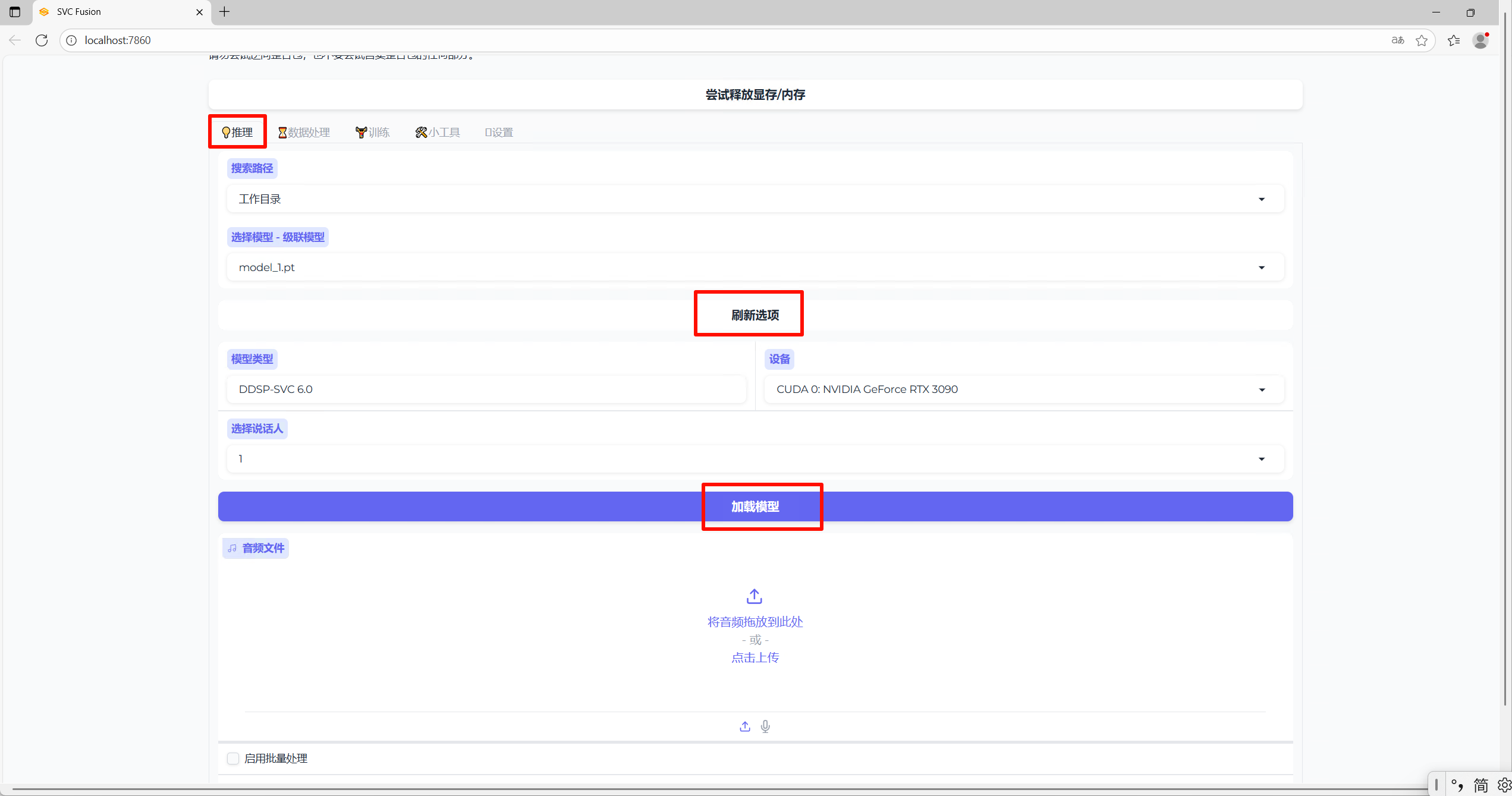
3.点击推理tab页点击加载模型弹出说话人即可
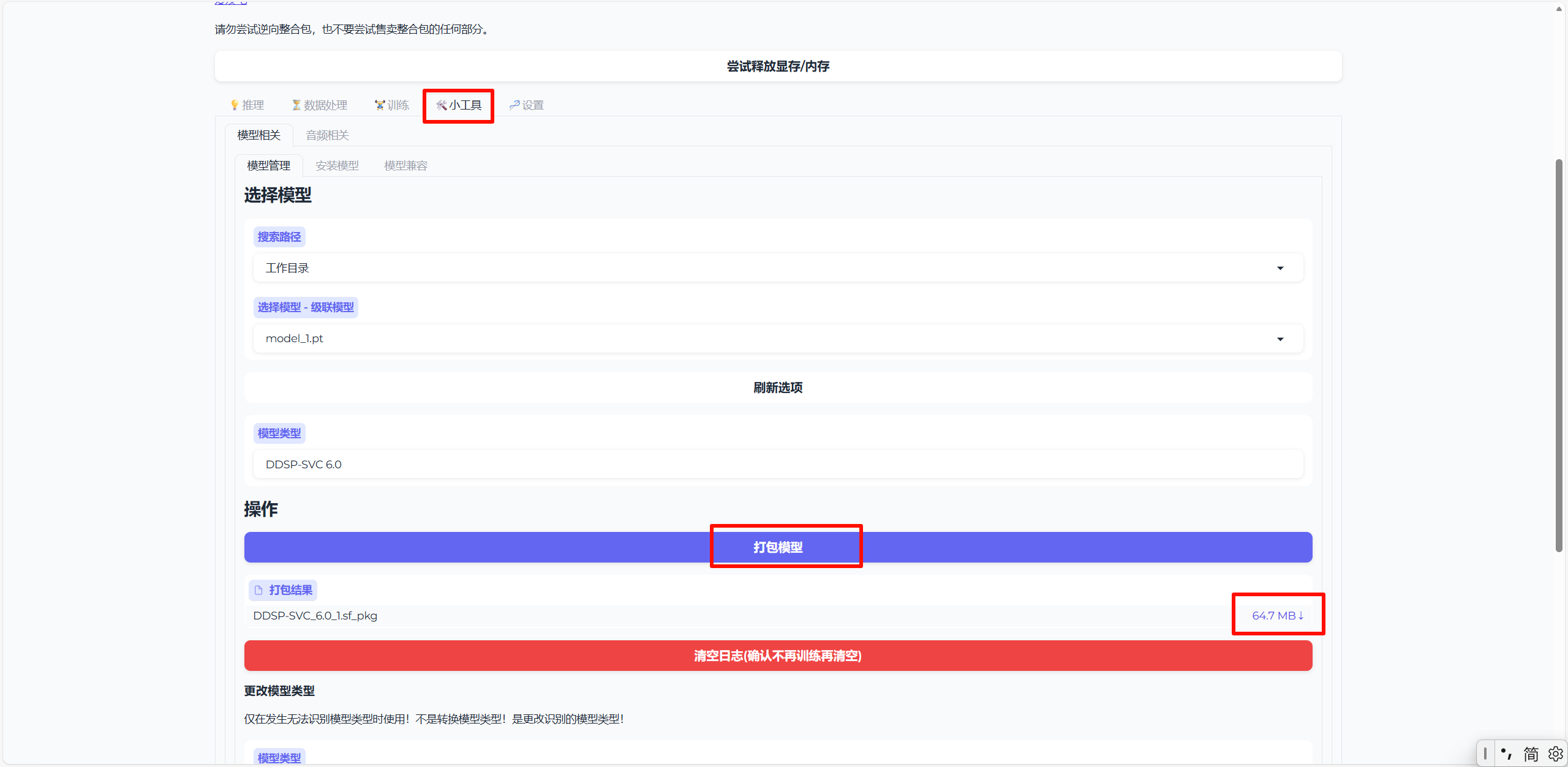
4.点击小工具tab页,点击打包模型即可,在打包结果上下载即可得到训练好的模型
注:以下为镜像师使用教程视频链接