【Qwen-7b】部署教程
一、模型介绍
Qwen-7B是一种基于transformer的仅解码器语言模型,其架构类似于LLaMA系列模型。 它在公开可用数据上进行了超过2.2万亿个标记的预训练,上下文长度为2048,覆盖了英文和中文为重点的一般和专业领域
显存要求
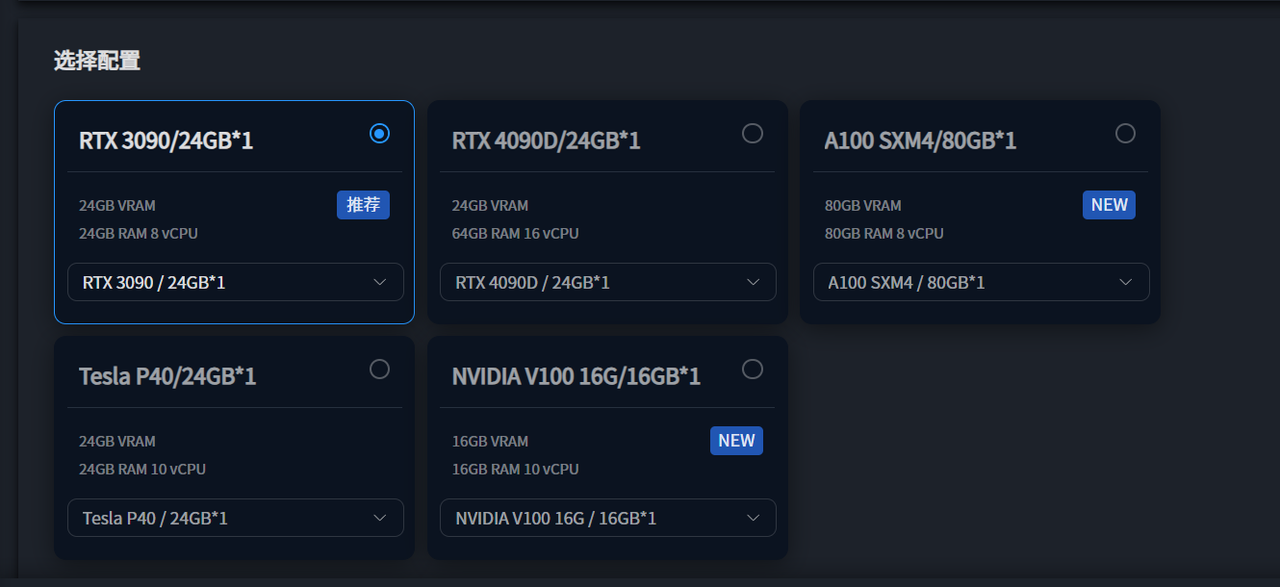
使用Qwen1.5的7B及14B模型时,必须选择24G显存以上的显卡
所以这里我们使用星海智算平台的显卡RTX3090并选择liunx镜像创建即可
如需详细创建教程可参考:快速使用教程
二、本地部署
1、克隆项目文件
1.1 克隆qwen项目到本地

成功创建实例后进入jupyter界面打开终端界面输入以下命令
bash
git clone https://github.com/QwenLM/Qwen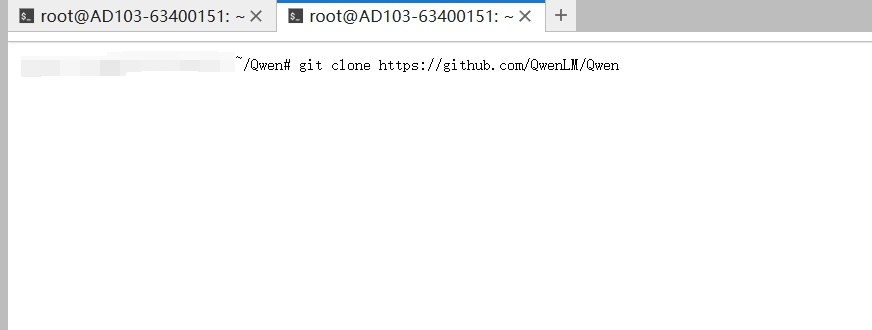
1.2 创建虚拟环境
bash
conda create -n qwen python=3.11
conda activate qwen1.3 创建安装依赖环境
bash
pip install -r requirements.txt1.4 安装GPU版本的pytorh
bash
conda install pytorch==2.2.2 torchvision==0.17.2 torchaudio==2.2.2 pytorch-cuda=12.1 -c pytorch -c nvidia2、下载模型文件
使用魔搭社区进行下载:
魔搭社区地址:https://modelscope.cn/models/qwen/Qwen-7B/files
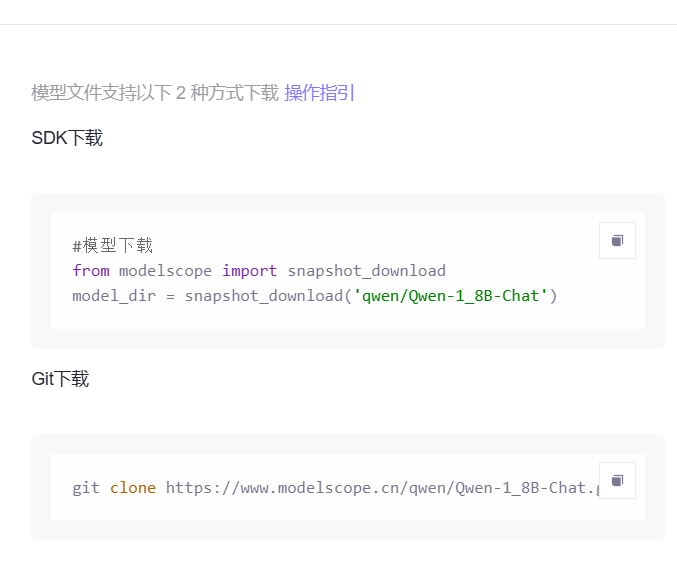
执行下载命令前,先安装:
bash
pip install modelscope在jupyter中选择py文件并打开
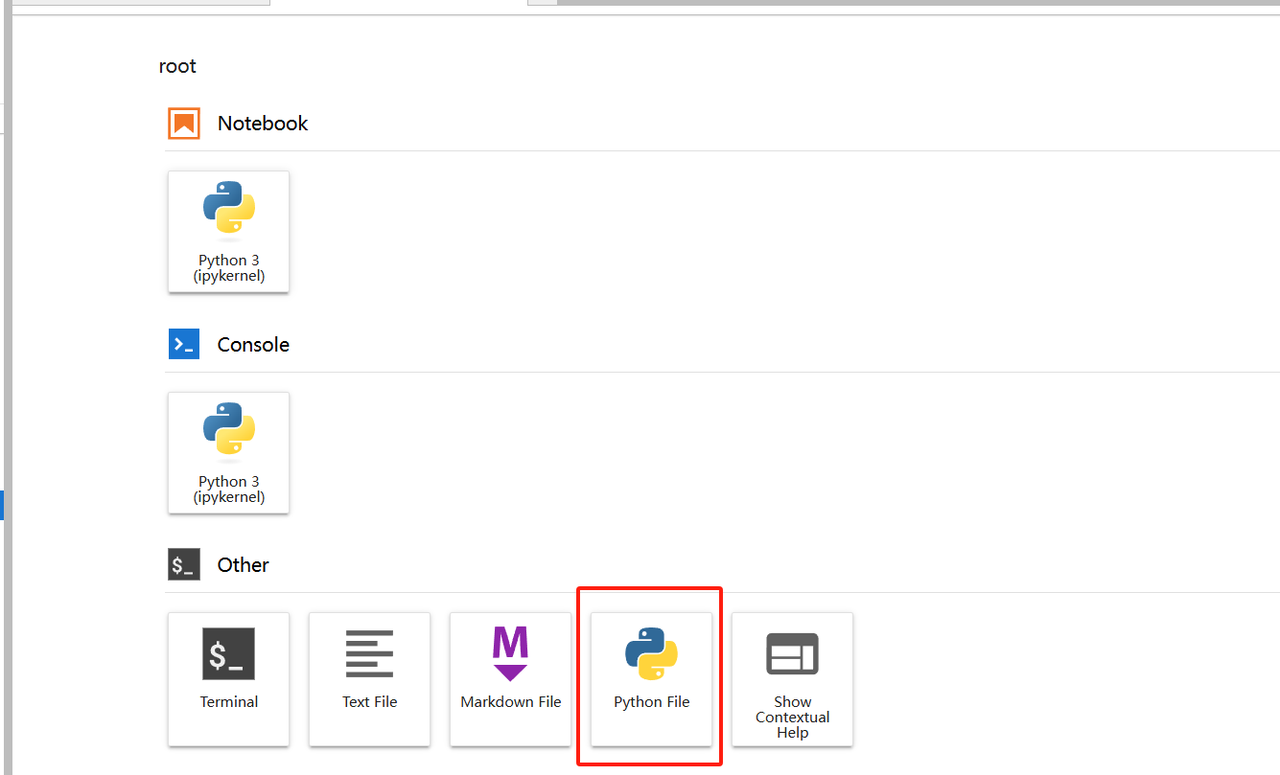
放入以下代码后保存任意名称即可,这里示例命名为don.py:
bash
#模型下载
from modelscope import snapshot_download
model_dir = snapshot_download('qwen/Qwen-7B-Chat', cache_dir='./model', revision='master')
随后在命令行中输入以下命令下载脚本
bash
Python don.py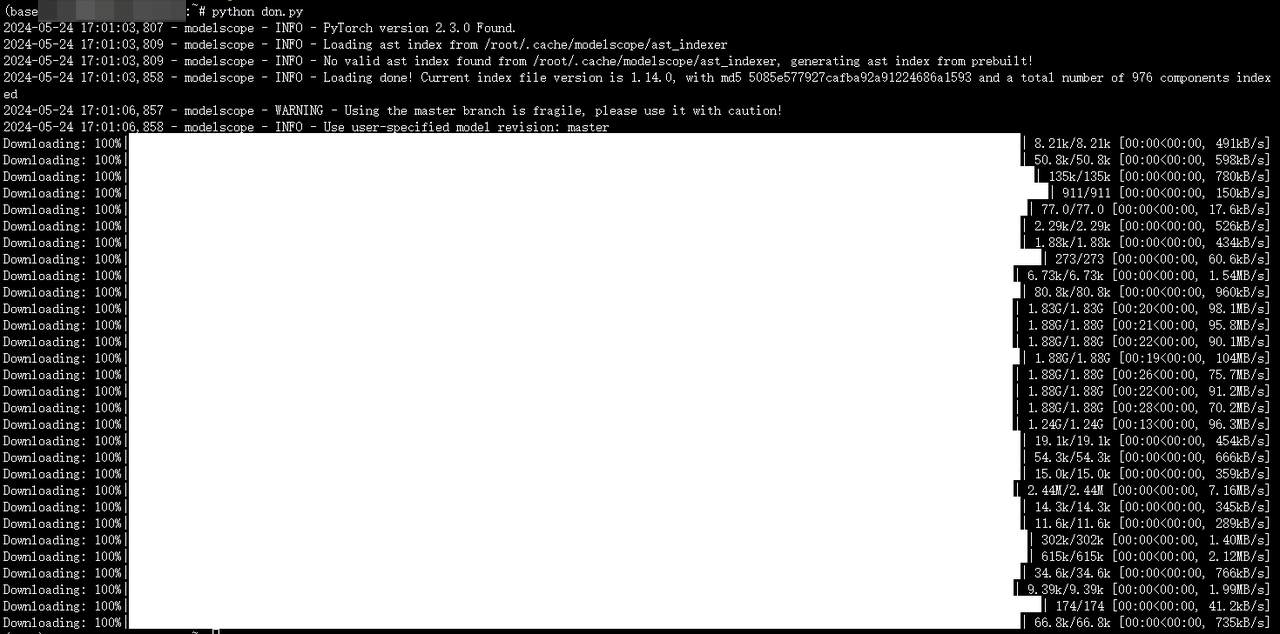
3、配置并启动demo脚本
在Qwen目录下终端运行:
bash
python cli_demo.py成功开启对话:
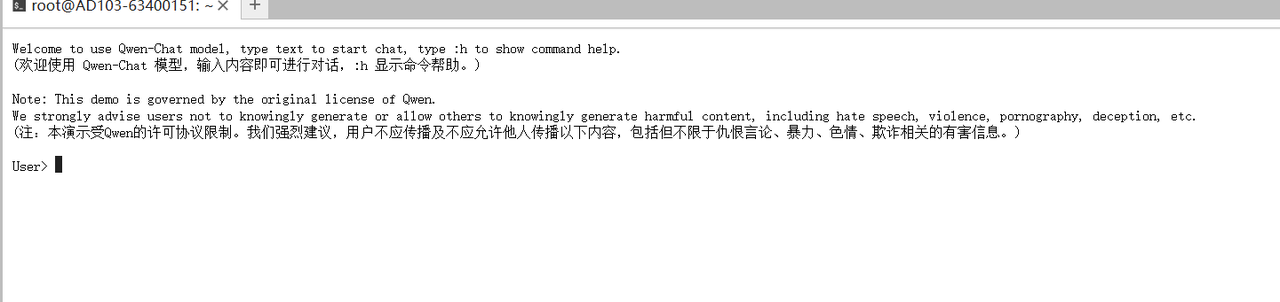
如需启动web可执行以下命令:
bash
Python web_demo.py如需在本地访问web可参考使用ssh隧道
