【Stable Video Diffusion】部署教程
一、模型介绍
Stable Video Diffusion(SVD)图像到视频是一种扩散模型,旨在利用静态图像作为条件帧,从而实现基于此单一图像输入的视频生成。它是 Stability AI 多样化的开源模型家族的一员。从现在看来,他们的产品跨足了图像、语言、音频、3D 和代码等各种领域。这种致力于增强人工智能的承诺,证明了他们的卓越奉献精神
使用用途:
Stable Video Diffusion 处于尖端的人工智能技术前沿,提供了一个强大的平台,用于视频生成和合成。这个创新模型旨在将静态图像转化为具有令人印象深刻的灵活性和自定义性的动态高质量视频。利用扩散模型架构,Stable Video Diffusion 以单一图像作为输入,并采用先进的算法生成无缝、逼真的视频。无论是为营销活动创建引人入胜的视觉内容,为娱乐目的制作逼真场景,还是让研究人员探索人工智能的新领域,Stable Video Diffusion 的应用多种多样,充满前景。
配置要求:
SVD:能够生成帧率14帧、分辨率 576x1024 的视频,最低显存要求16G;
SVD-XT:SVD 的 finetune 升级版,分辨率576x1024,但能够生成帧率 25 帧的视频,最低显存为20G
二、模型部署
1、SVD模型安装
登入星海智算平台选择所需镜像并创建实例
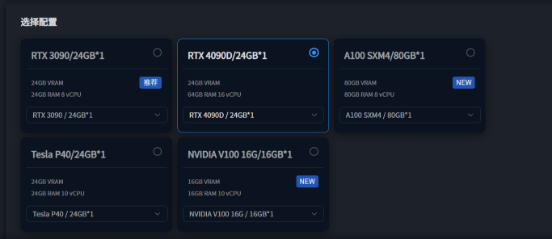
这里选择4090D,显存足够
创建实例教程详见快速使用教程
创建完成后进入Jupyter界面
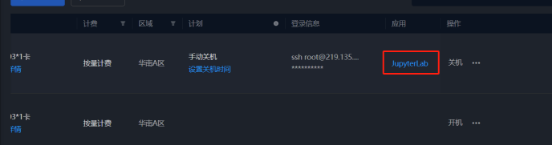
输入一下命令克隆SVD项目
git clone https://github.com/Stability-AI/generative-models
cd generative-models
在克隆后的目录中下载模型,这里使用huggingface.co的镜像站点hf-mirror.com进行下载:
| SVD | https://hf-mirror.com/stabilityai/stable-video-diffusion-img2vid-xt |
|---|---|
| SVD-XT | https://hf-mirror.com/stabilityai/stable-video-diffusion-img2vid |
在generative-models目录下创建checkpoints目录后将模型存放在此:
mkdir checkpoints
cd checkpoints出于演示目的这里选择25帧的模型SVD-XT下载,个人使用时可以按需选择任意一个模型,使用以下命令下载模型:
wget https://hf-mirror.com/stabilityai/stable-video-diffusion-img2vid/resolve/main/svd.safetensors
python环境配置
conda create --name svd python=3.10 -y
source activate svd
pip3 install -r requirements/pt2.txt
pip3 install .
如遇超时报错,大概率为网络问题可使用学术加速来规避此问题
# 加速
source /etc/network_turbo
# 取消加速
unset http_proxy && unset https_proxy2、模型运行
使用命令运行:
cd generative-models
streamlit run scripts/demo/video_sampling.py --server.address 0.0.0.0 --server.port 7862
如果出现此界面下面下载模型操作可忽略
启动时,还会下载两个模型,也可以手动去下载,放到以下目录:
/root/.cache/huggingface/hub/models–laion–CLIP-ViT-H-14-laion2B-s32B-b79K
/root/.cache/clip/ViT-L-14.pt下载地址:
https://hf-mirror.com/laion/CLIP-ViT-H-14-laion2B-s32B-b79K/tree/main
models–laion–CLIP-ViT-H-14-laion2B-s32B-b79K下载后
执行以下命令:
bashcp models--laion--CLIP-ViT-H-14-laion2B-s32B-b79K.tar /root/.cache/huggingface/hub/ cd /root/.cache/huggingface/hub/ tar -zxvf models--laion--CLIP-ViT-H-14-laion2B-s32B-b79K.tar继续运行,如果报错
bashfrom scripts.demo.streamlit_helpers import * ModuleNotFoundError: No module named 'scripts'添加环境变量
bashRUN echo 'export PYTHONPATH=/generative-models:$PYTHONPATH' >> /root/.bashrc source /root/.bashrc再次启动
3、web界面操作
这里使用ssh隧道来使本地电脑可访问web
如何使用ssh连接请查看此文档SSH 隧道
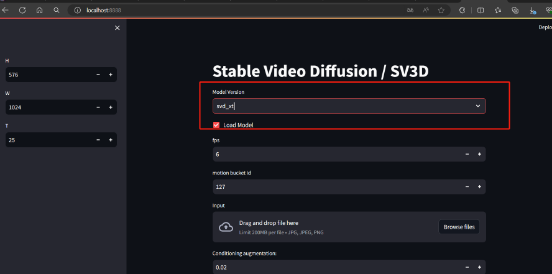
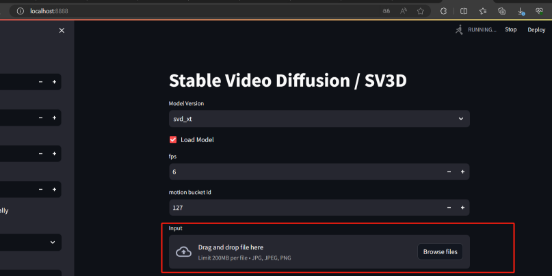
进入web界面后选择你下载在checkpoints中的模型,并点击Load Model即可,这里我选择SVD_xt模型加载,此时加载完成后台会出现报错
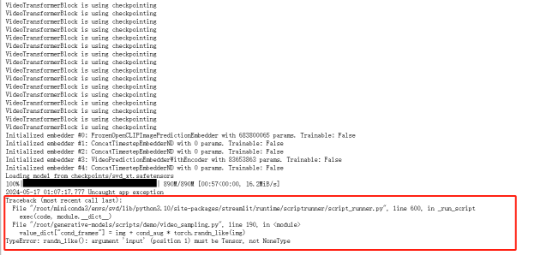
此报错说明未上传图片,在web界面中选择图片即可
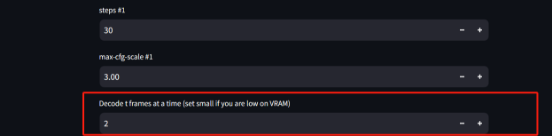
此参数建议选小一点,不如容易报显存错误
其他参数保持不变点击"Sample"
处理完之后,可以看一下视频,视频保存在:
generative-models/outputs/demo/vid/svd_image_decoder/samples4、web参数说明

FPS
控制视频生成视频的帧数,取值范围【5~30】
比如:SVD 模型出来14帧的数据,然后编码成6帧每秒的视频,那最后输出的视频就是 14/6约2秒这样的视频。
Motion bucket id
控制视频中的动作,数值 越高,动作越多。 取值范围【0~255】
max-cfg-scale
控制生成的帧与第一帧的变化,第一帧默认1,最后一帧是max-cfg-scale,数值越大,变化越大;
也就是数值越大,生成的视频变化也会更大。
Decode t frames at a time (set small if you are low on VRAM)
编码成视频时,一次编码多少帧,设置为1~4。
生成的视频,是多少秒,怎么计算出来
视频时长 = T/fps
5、报错
报错1:如果没有安装ffmpeg,就安装一下
apt install ffmpeg报错2:
TypeError: TiffWriter.write() got an unexpected keyword argument 'fps'解决办法:安装
pip install imageio==2.19.3
pip install imageio-ffmpeg==0.4.7