EchomimicV2镜像使用教程
一、镜像概述
1、加速版
占用100G磁盘,更快的生成速度 
2、基础版
占用80G磁盘 
3、EchomimicV2
EchoMimicV2是由阿里蚂蚁集团推出的半身人体AI数字人项目,以下是对其的详细介绍:
3.1、项目背景与简介
推出团队:蚂蚁集团支付宝终端算法数据技术团队。
项目定位:旨在通过音频、图像和手势序列生成高质量的半身人物动画视频。
发布时间:在2024年11月21日发布了其代码和模型,并在之后进行了更新,包括加速模型和管道的发布,推理速度提高了10倍。
3.2、技术特点与优势
音频驱动人物动作:EchoMimicV2能够根据音频输入自动生成精准的面部表情和身体动作,实现音频与动画的同步。
多语言支持:支持中文和英文等多语言输入,根据语言内容生成相应的动画。
高度还原自然动作:使用先进的AI技术,生成高保真的面部表情、嘴唇同步以及身体动作。
情感表达与细节丰富:能够捕捉细腻的情感变化,展现人物的情感状态,使角色更加生动、真实。
简化控制条件:相较于前代产品,EchoMimicV2减少了动画生成过程中所需的复杂条件,让动画制作更为简便。
3.3、技术框架与核心组件
主干框架:由参考UNet(Reference UNet)与去噪UNet(Denoising UNet)组成。
核心组件: 手部关键点序列编码器:接收一张手部关键点图作为输入,输出编码后的关键点特征。
语音特征编码器:将语音信号转化为相应的语音特征向量,便于后续进行语音-图像间的交叉注意力计算。
去噪UNet网络:接收噪声和条件信号(即语音特征)作为输入,输出对应的图像特征,实现从语音特征到图像生成的转换。
训练策略:采用音频-姿势动态协调(Audio-Pose Dynamic Harmonization,APDH)策略,包括姿势采样(Pose Sampling)与音频扩散(Audio Diffusion),以增强模型对多模态输入的适应性和鲁棒性。
3.4、应用场景与价值
虚拟角色和数字人:用于创建高度逼真的虚拟角色和数字人,如虚拟主播、AI助手等。
影视制作与动画创作:提高动画制作效率,减少人工动画的制作时间和成本。
游戏开发:用于游戏中的动态角色和NPC,增强游戏中的互动性和沉浸感。
虚拟互动与直播:根据语音输入实时生成虚拟人物的动作和表情,使虚拟主播与观众之间的互动更加生动和自然。
AI客服与智能助手:通过语音与用户的对话来动态生成表情和动作,提升用户体验。
教育与培训:用于教育游戏或互动学习,提供更加直观的互动体验。
3.5、开源与社区
开源项目:EchoMimicV2作为一个开源项目,可以免费使用其代码和模型。
项目主页与代码仓库: 项目主页:https://antgroup.github.io/ai/echomimic_v2
GitHub仓库:https://github.com/antgroup/echomimic_v2
综上所述,EchoMimicV2是一项具有广泛应用前景和价值的AI数字人技术项目,它通过音频、图像和手势序列生成高质量的半身人物动画视频,为虚拟角色和数字人的创建、影视制作与动画创作、游戏开发以及虚拟互动与直播等领域带来了全新的解决方案。
二、镜像使用
1、加速版
1.1、打开文件夹
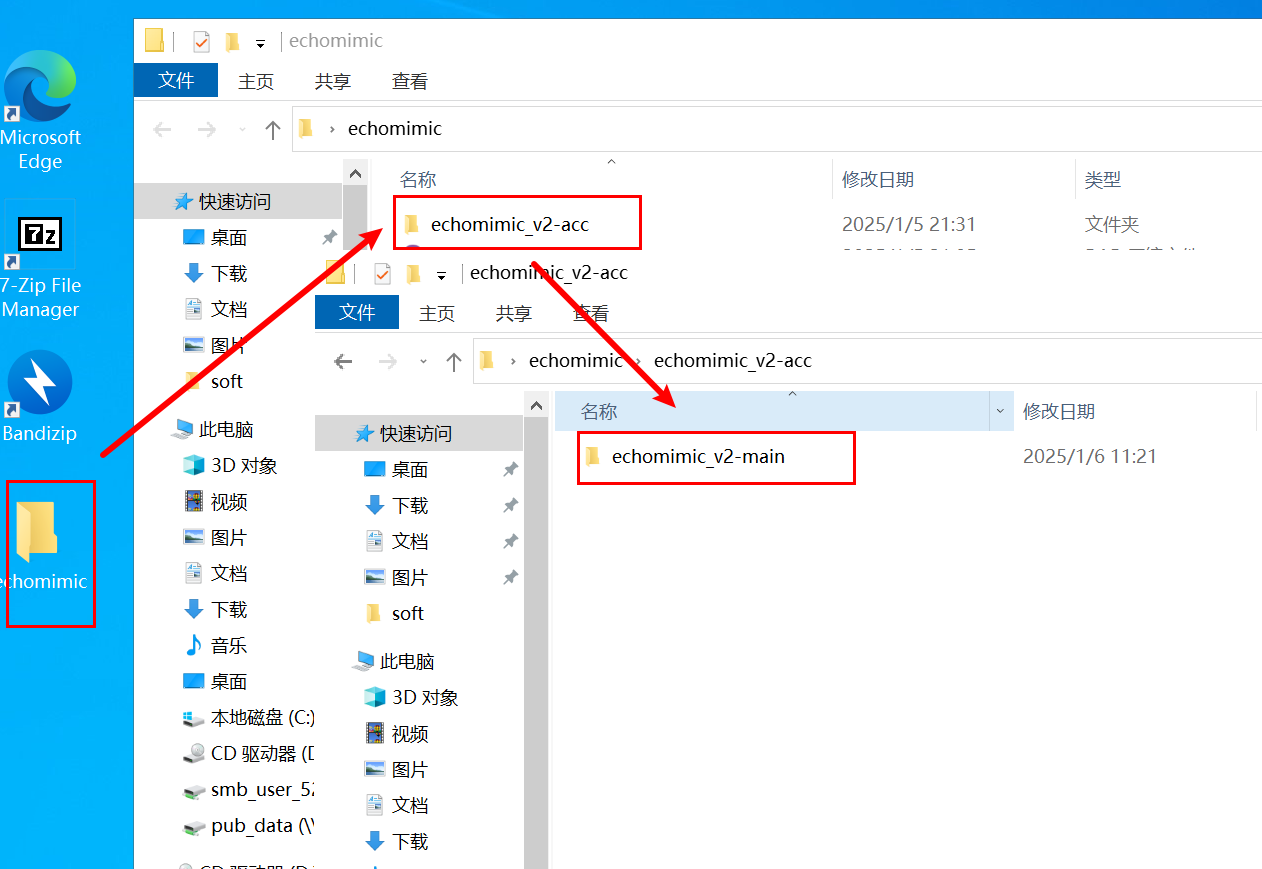
1.2、检测运行环境
点击检测运行环境.bat,检测是否依赖缺失。 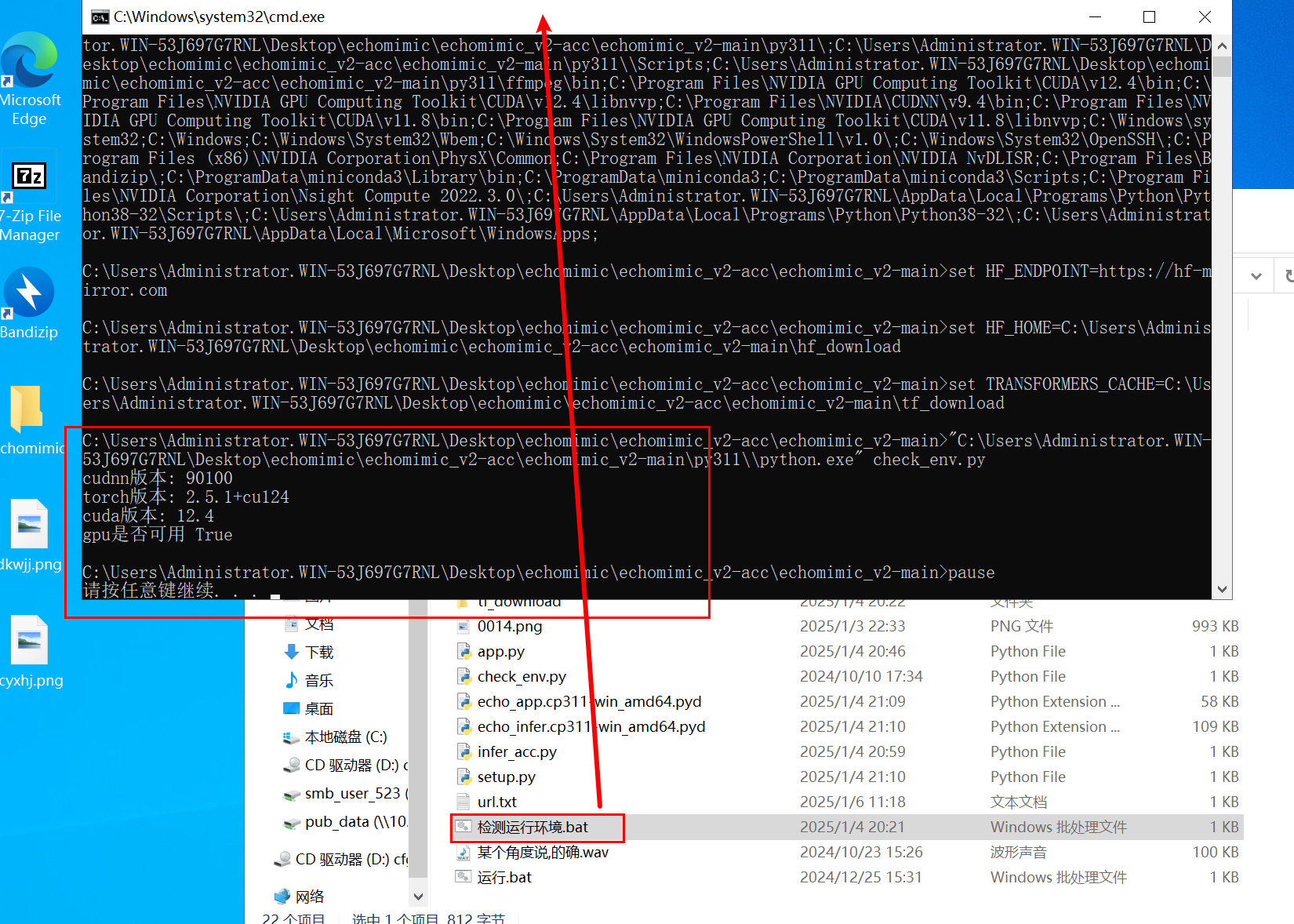
1.3、运行应用
确认无误后,点击运行.bat运行程序。 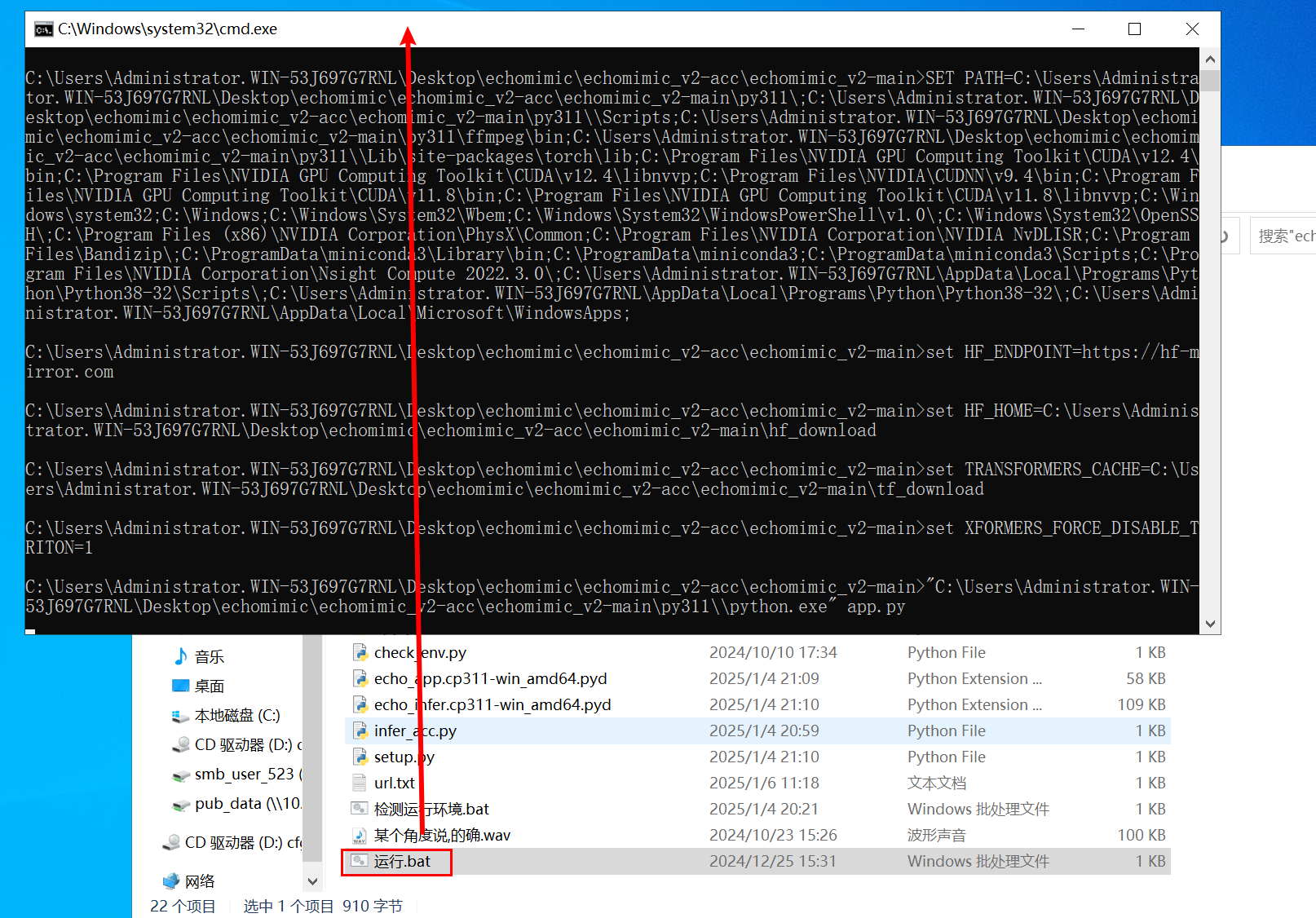
1.4、应用界面
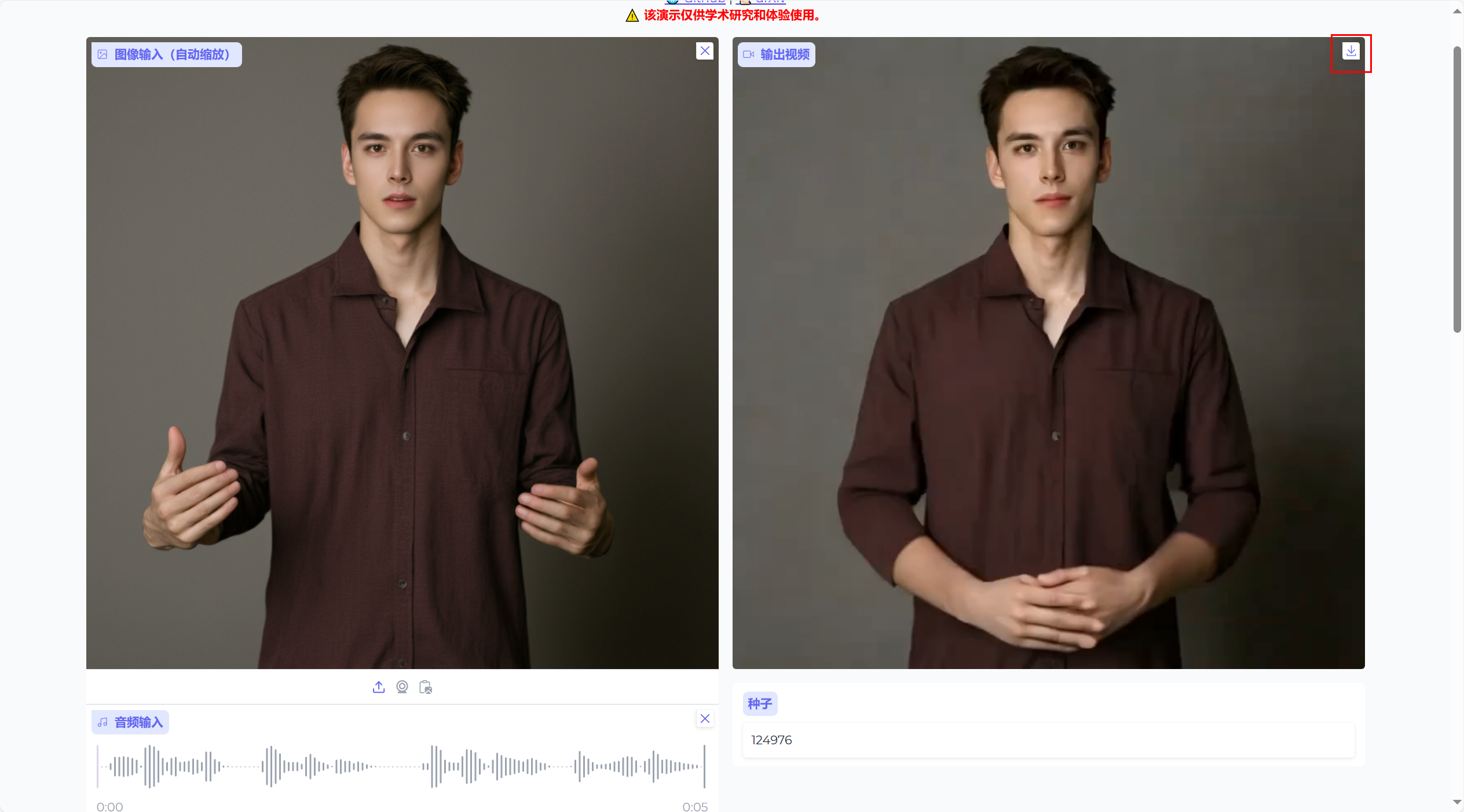
等待程序运行结束,会自动打开应用网页。 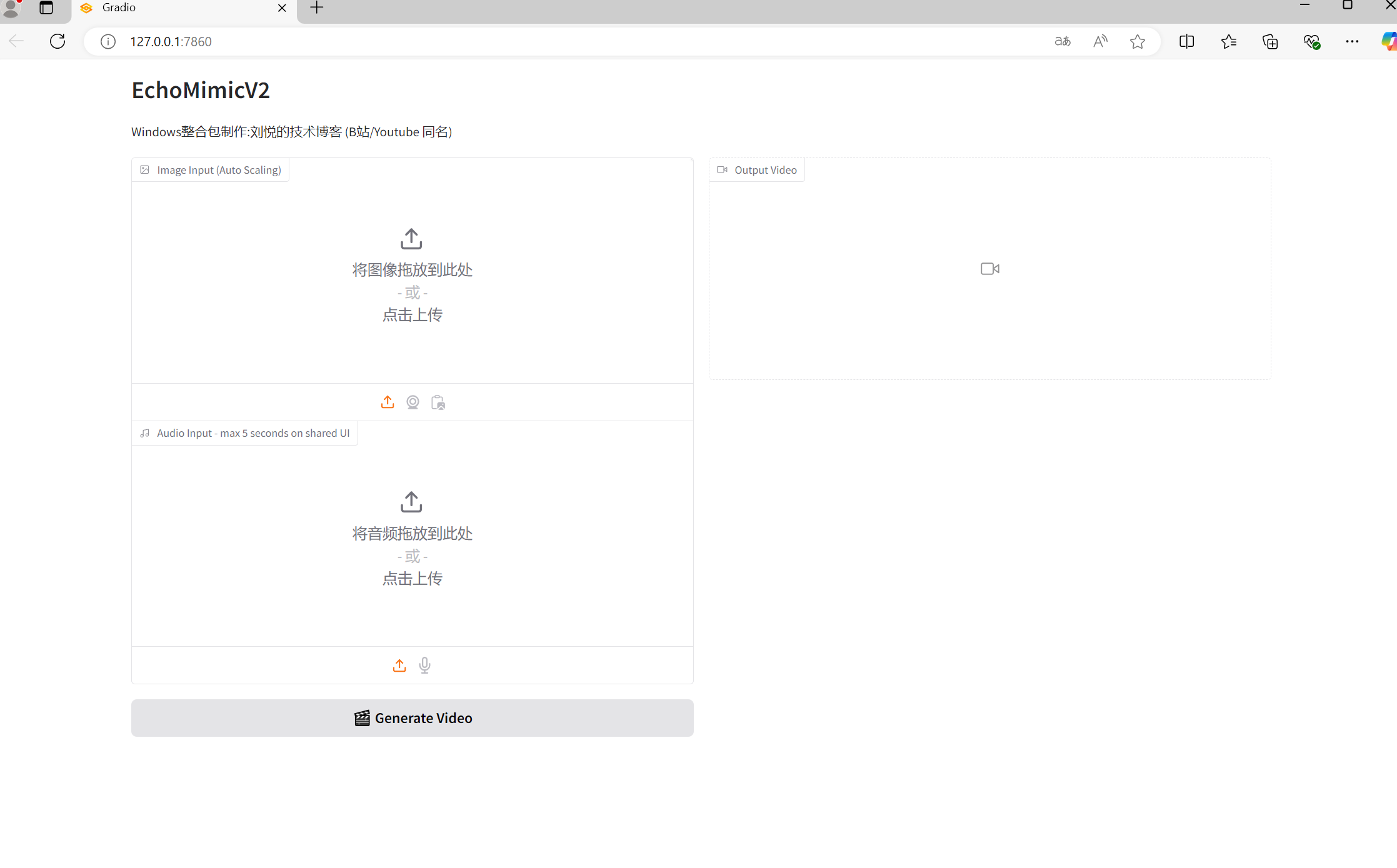
1.5、生成视频
上传相关图片、音频之后,点击Generate Video按钮即可生成视频。 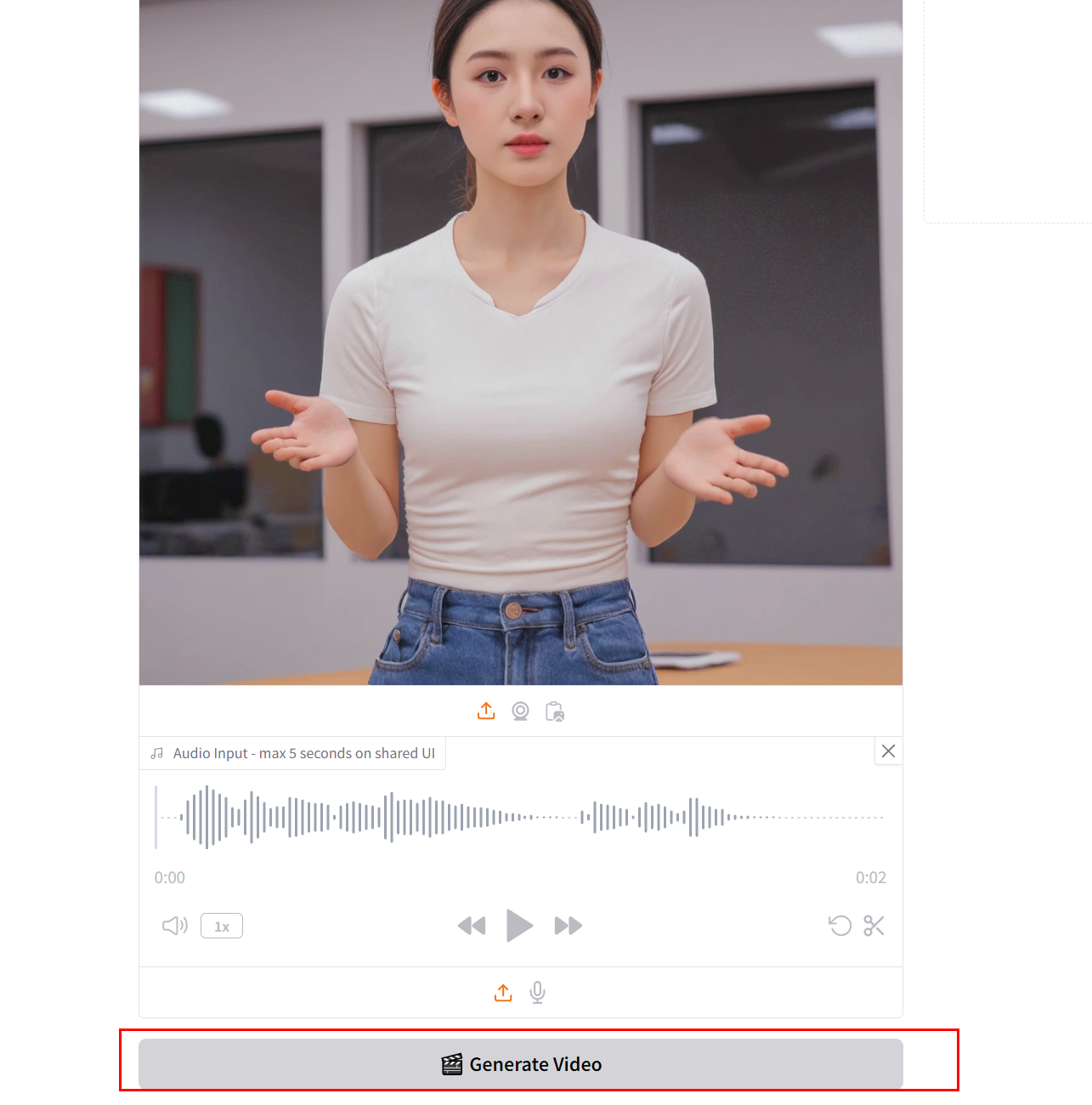
2、基础版
2.1、启动程序
打开文件夹,点击启动程序.bat,并等待程序运行。 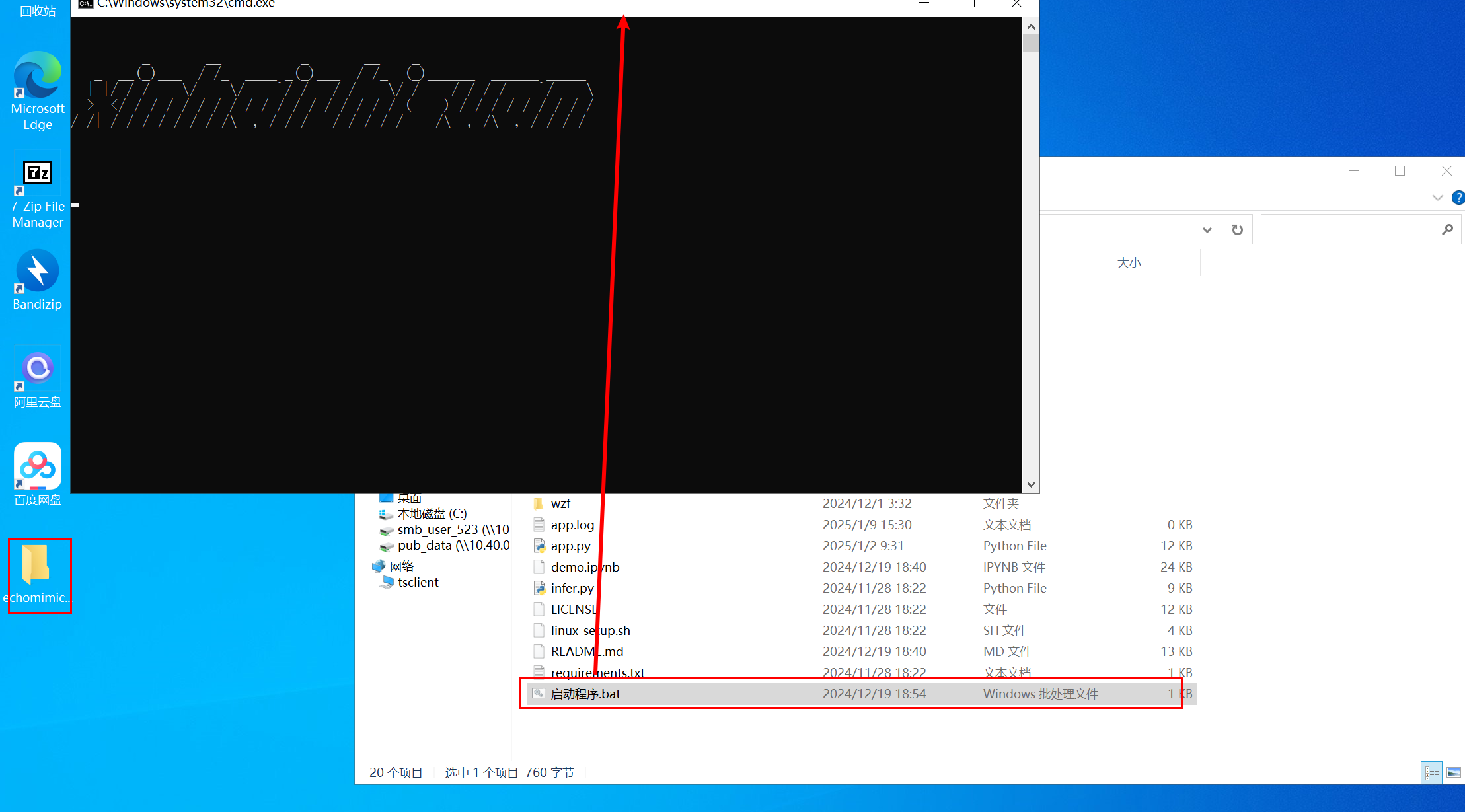
2.2、应用界面
打开界面如图 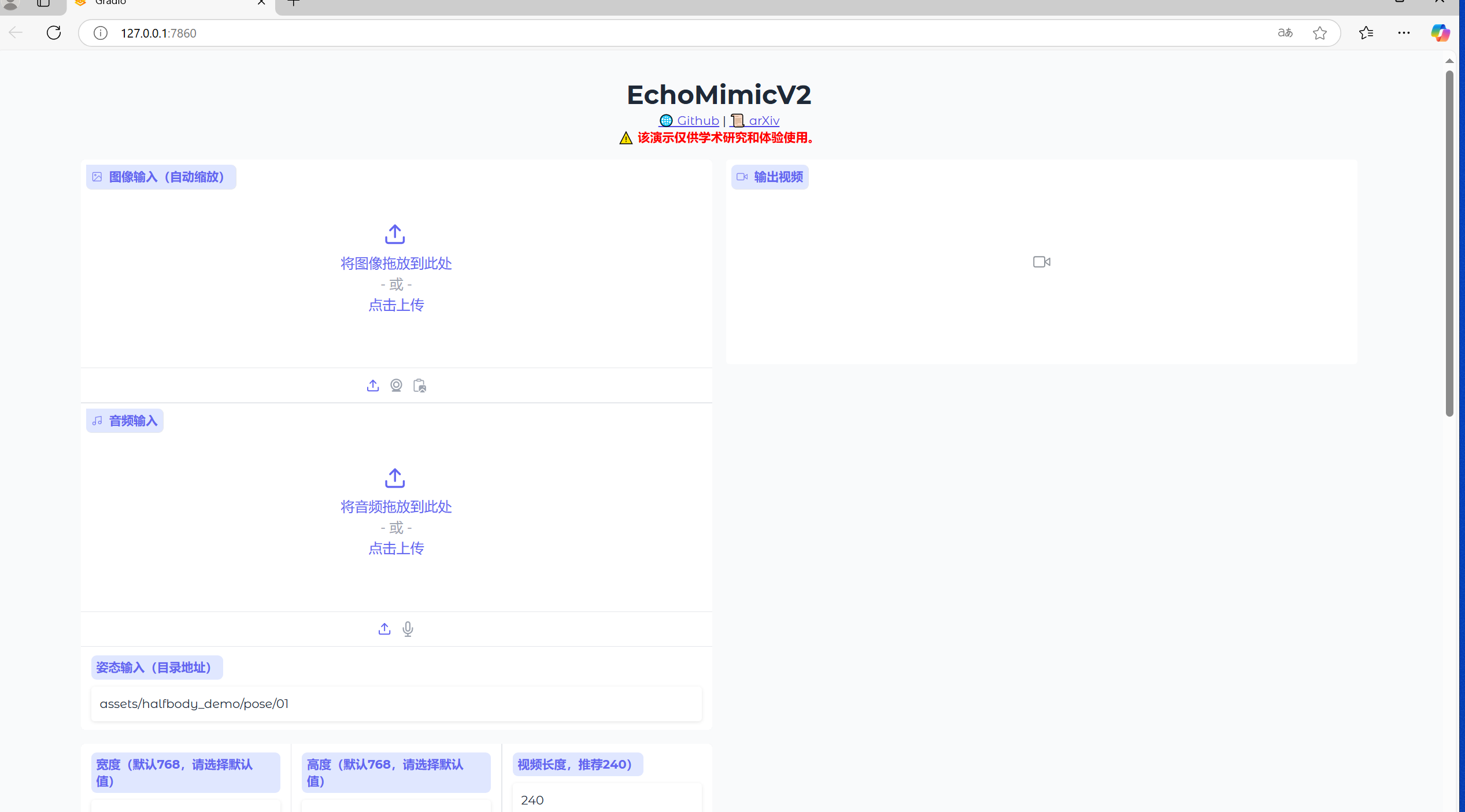
2.3、生成视频
上传相关图片、音频之后,调整相关参数,点击生成视频按钮,即可生成视频。 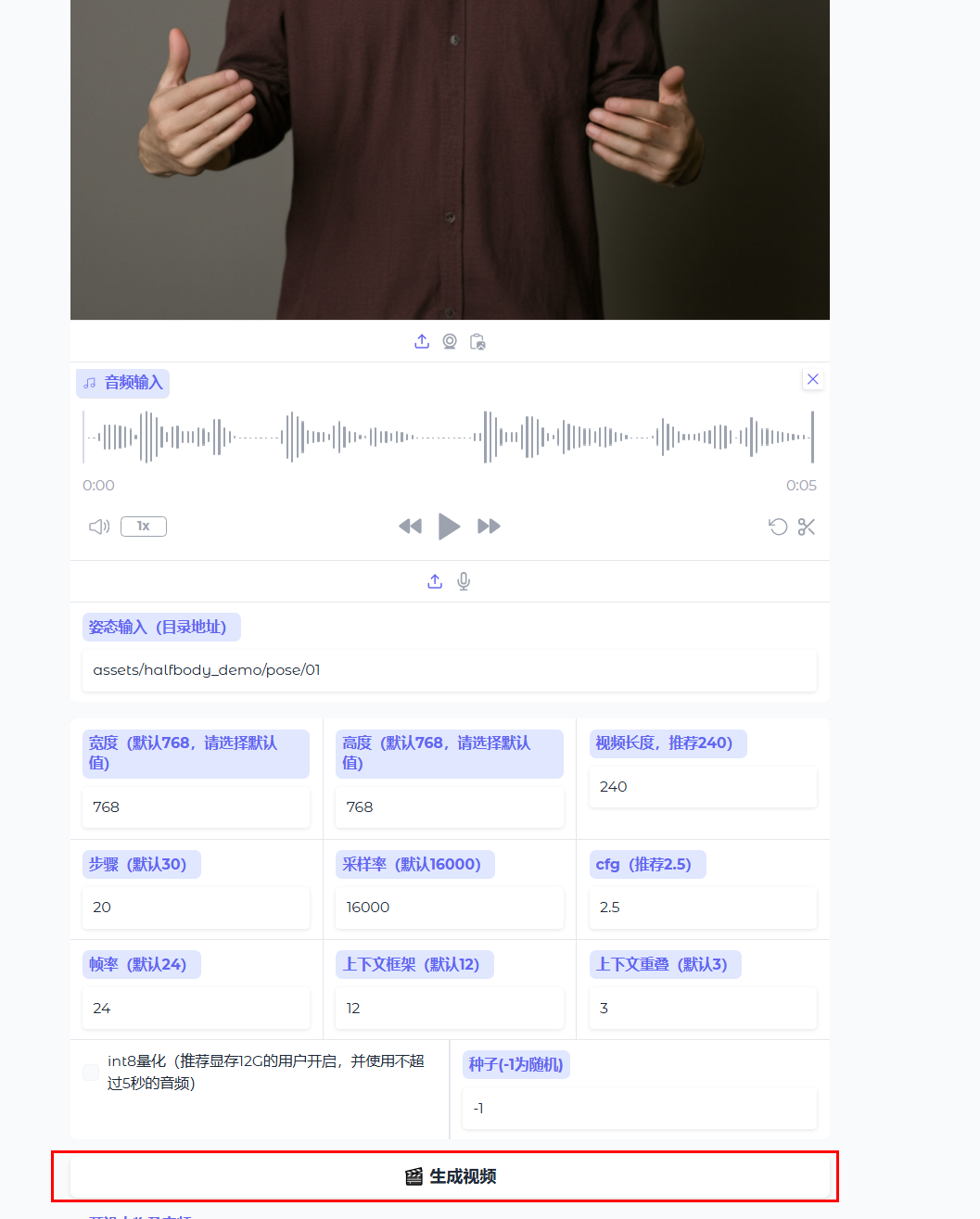
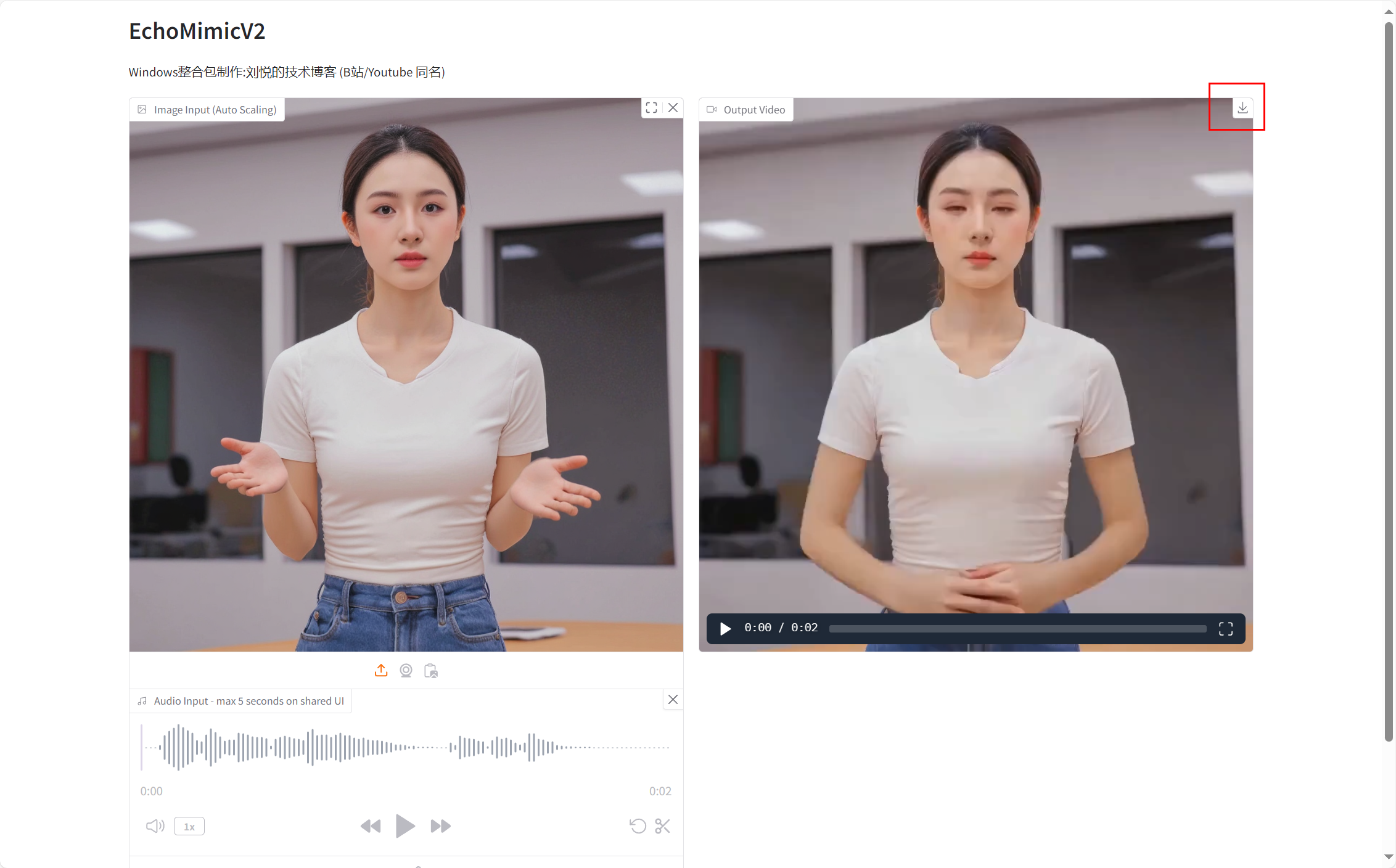
三、使用结果
1、加速版
2、基础版